Trong hơn một thập kỷ, các công nghệ giảm dung lượng dữ liệu như khử trùng lặp và nén đã được tiếp thị như giải pháp phổ quát cho bài toán chi phí và mở rộng lưu trữ. Với các workload doanh nghiệp truyền thống, những kỹ thuật này thực sự mang lại giá trị.
Nhưng AI đã thay đổi cuộc chơi.
Khi các tổ chức xây dựng các pipeline suy luận AI dựa trên khối lượng dữ liệu phi cấu trúc khổng lồ, nhiều đội ngũ đang phải đối mặt với một sự thật không mấy dễ chịu:
Giảm dung lượng dữ liệu hầu như không mang lại lợi ích kinh tế cho suy luận AI. Trong một số trường hợp, nó còn trực tiếp làm suy giảm hiệu năng và hiệu quả chi phí.
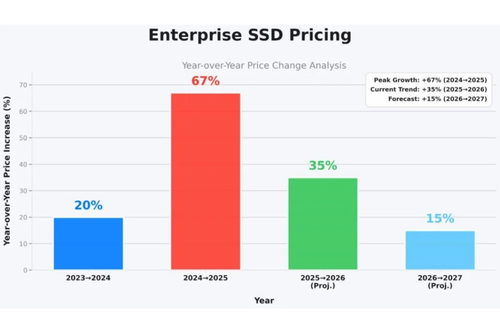
Đồng thời, các đợt tăng giá SSD mạnh mẽ được dự báo từ năm 2026 trở đi đang buộc các kiến trúc sư AI phải xem xét lại giả định lâu nay về “all-flash cho mọi thứ”. Kết quả là ngày càng nhiều đội ngũ đi đến kết luận rằng kiến trúc dựa trên HDD là một lựa chọn khả thi cho nhiều workload suy luận AI, đặc biệt khi yếu tố kinh tế ngày càng trở nên quan trọng.
Bài toán giá SSD năm 2026
Cho đến gần đây, nhiều tổ chức vẫn chấp nhận sự kém hiệu quả của lưu trữ all-flash vì giá SSD liên tục giảm, đủ để che giấu các sai lầm kiến trúc. Giai đoạn đó đang khép lại.
Những thay đổi từ năm 2026
Hợp nhất sản xuất NAND
Chi phí đầu tư ngày càng cao cho các node công nghệ tiên tiến
Nhu cầu tăng mạnh từ các cụm huấn luyện AI
Hạn chế nguồn cung do các hyperscaler chi phối
Hệ quả là giá SSD tăng đáng kể, đặc biệt với các ổ enterprise dung lượng lớn. Với các đội AI đang xây dựng pipeline suy luận quy mô petabyte, thực tế trở nên rất rõ ràng:
Lưu trữ dữ liệu suy luận có giá trị thấp, chủ yếu đọc, trên SSD không còn hợp lý về mặt kinh tế.
Điều gì đang thúc đẩy giá SSD tăng mạnh từ 2026 trở đi
- Kỷ luật nguồn cung NAND mang tính cấu trúc
Các nhà sản xuất NAND đã cắt giảm mạnh công suất trong giai đoạn suy thoái 2022-2023. Khác với các chu kỳ trước, họ không còn chạy đua mở rộng sản xuất.
Ít fab hơn
Khởi động wafer thận trọng
Thời gian triển khai node mới dài hơn
Điều này tạo ra sự khan hiếm kéo dài, chứ không phải biến động ngắn hạn.
- Cụm huấn luyện AI tiêu thụ phần lớn SSD cao cấp
Các môi trường huấn luyện AI quy mô lớn sử dụng:
- SSD enterprise dung lượng cao
- Các dòng có độ bền cao
- Ổ đĩa được chứng nhận tùy chỉnh
Các hyperscaler và phòng lab AI hàng đầu sẵn sàng trả giá cao hơn doanh nghiệp thông thường, hút nguồn cung SSD về phía họ thông qua các hợp đồng dài hạn.
- NAND tiên tiến ngày càng đắt đỏ
Các node NAND hiện đại đòi hỏi:
- Nhiều lớp hơn
- Chi phí đầu tư cao hơhơn
- Tỷ lệ yield thấp trong giai đoạn đầu
Chi phí trên mỗi wafer tăng lên và được chuyển thẳng xuống khách hàng thay vì được nhà sản xuất hấp thụ.
- SSD đang bị sử dụng sai chỗ
Nhiều pipeline AI, đặc biệt là pipeline suy luận, lưu trữ:
- Hàng petabyte dữ liệu video và hình ảnh phi cấu trúc
- Các tập dữ liệu lạnh hoặc ấm, truy cập có thể dự đoán
- Dữ liệu không hưởng lợi từ nén hay khử trùng lặp
Tuy nhiên, chúng vẫn được đặt trên SSD vì:
- “All-flash” nghe có vẻ an toàn
- Giả định cũ chưa được xem xét lại
- Marketing về giảm dung lượng che giấu chi phí thực
Khi giá tăng, sự lệch pha này trở nên không thể bỏ qua.
- Pipeline suy luận khuếch đại vấn đề chi phí
Suy luận AI không phải là một loại workload duy nhất. Các quy trình suy luận thời gian thực như lái xe tự động, phát hiện gian lận hay hệ thống gợi ý đòi hỏi độ trễ cấp NVMe, nơi mỗi mili giây đều ảnh hưởng trực tiếp đến kết quả – HDD không phù hợp cho đường suy luận chính.
Ngược lại, suy luận theo lô, phân tích video quy mô lớn, xử lý hình ảnh và các giai đoạn tiền xử lý lại bị giới hạn bởi thông lượng hơn là độ trễ. Các workload này vận hành trên tập dữ liệu phi cấu trúc bền vững, quy mô petabyte, nơi băng thông ổn định và chi phí trên mỗi TB quan trọng hơn micro-giây độ trễ.
Trong các kịch bản đó, kiến trúc dựa trên HDD kết hợp cache thông minh và mạng băng thông cao không phải là thỏa hiệp, mà là lựa chọn đúng đắn cả về mặt kiến trúc lẫn kinh tế.
Các workload suy luận thường có đặc điểm:
- Đọc là chủ yếu
- Mở rộng theo chiều ngang
- Dữ liệu tồn tại lâu dài
- Nhạy cảm với chi phí
Chúng cần băng thông và dung lượng, không phải độ trễ cực thấp.
Chi phí ẩn của giảm dung lượng dữ liệu trong suy luận
Ngay cả khi giảm dung lượng mang lại một chút lợi ích về capacity, nó vẫn tạo ra các hệ quả hệ thống nghiêm trọng:
- Tiêu tốn CPU cho nén và giải nén
- Gia tăng metadata
- Tăng tail latency
- Giảm tính ổn định hiệu năng khi tải đồng thời
Trong môi trường suy luận nơi mili giây có ý nghĩa, những đánh đổi này thường không thể chấp nhận. Vì vậy, nhiều đội AI âm thầm tắt các tính năng giảm dung lượng sau khi triển khai, dù chúng từng là yếu tố trong quyết định mua ban đầu.
Vì sao khử trùng lặp không hiệu quả với dữ liệu AI
Khử trùng lặp dựa trên giả định rằng dữ liệu có các khối giống hệt hoặc gần giống nhau. Giả định này gần như không tồn tại với dữ liệu AI.
Hai khung hình video có thể trông giống nhau với con người, nhưng khác hoàn toàn ở mức nhị phân
Thay đổi nhỏ về ánh sáng, góc quay hay chuyển động tạo ra các khối dữ liệu hoàn toàn khác
Hình ảnh và video thường đã được mã hóa sẵn
Embedding và tensor có mật độ cao và rất độc nhất
Trên thực tế, nhiều khách hàng chỉ đạt tỷ lệ khử trùng lặp dưới 1,1 lần – gần như vô nghĩa khi tính cả chi phí metadata và CPU.
Vì sao nén dữ liệu mang lại rất ít giá trị
Phần lớn dữ liệu AI đã được nén ngay từ nguồn:
Camera nén video
Pipeline hình ảnh nén ảnh
Âm thanh được mã hóa
Đặc trưng ML được tối ưu mật độ
Cố gắng nén thêm thường chỉ mang lại:
- Tiết kiệm dung lượng không đáng kể
- Tăng tải CPU
- Tăng độ trễ đọc
- Giảm thông lượng khi hệ thống chịu tải
Với pipeline suy luận, nơi độ ổn định độ trễ và thông lượng quan trọng hơn hiệu quả dung lượng logic, đây là một sự đánh đổi bất lợi.
Lời hứa sai lầm của “giảm dung lượng ở quy mô lớn”
Một số nhà cung cấp vẫn xem giảm dung lượng là trụ cột kinh tế cho lưu trữ AI. Vấn đề không nằm ở cách triển khai, mà ở giả định ban đầu.
Giảm dung lượng giả định rằng dữ liệu có tính lặp, dễ nén và dung lượng logic là yếu tố chi phí chính. Dữ liệu suy luận AI phá vỡ cả ba giả định này.
Trong thực tế, dữ liệu phi cấu trúc chiếm phần lớn pipeline AI và không hưởng lợi từ giảm dung lượng, dù vẫn có giá trị nhất định với dữ liệu văn bản hay log có cấu trúc.
Vì sao HDD đang quay trở lại trong kiến trúc AI
HDD không quay lại vì “đủ dùng”, mà vì nó phù hợp với vật lý và kinh tế của dữ liệu suy luận AI.
HDD cung cấp:
- Thông lượng đọc tuần tự lớn
- Chi phí trên mỗi TB thấp
- Độ trễ dự đoán được ở quy mô lớn
- Không phụ thuộc vào giảm dung lượng
- Phù hợp với dữ liệu phi cấu trúc bền vững
Đặc biệt khi kết hợp với cache thông minh, kiến trúc phân tầng, mạng băng thông cao và hệ thống file song song hiện đại.
Thiết kế lưu trữ AI dựa trên thực tế, không phải marketing
Thế hệ quyết định hạ tầng AI tiếp theo sẽ được dẫn dắt bởi chủ nghĩa hiện thực kinh tế, không phải tư duy lưu trữ doanh nghiệp cũ.
Các đội AI hiệu quả đang:
- Tách riêng lưu trữ huấn luyện và suy luận
- Dùng SSD ở nơi độ trễ thực sự quan trọng
- Triển khai HDD ở nơi dung lượng và thông lượng là ưu tiên
- Bỏ qua các tuyên bố giảm dung lượng không kiểm chứng
DDN EXAScaler cho phép kết hợp SSD, HDD hoặc cả hai để thiết kế giải pháp cân bằng hiệu năng, dung lượng và chi phí. Với công nghệ Hot Pools tích hợp sẵn, dữ liệu nóng có thể nằm trên SSD, trong khi khối lượng dữ liệu phi cấu trúc lớn được lưu trữ kinh tế trên HDD mà không làm gián đoạn pipeline suy luận.
Cách tiếp cận lai này giúp duy trì thông lượng cao, giảm thời gian GPU nhàn rỗi và cho phép mở rộng suy luận một cách bền vững khi áp lực giá SSD ngày càng gia tăng.
Unitas cam kết đồng hành cùng doanh nghiệp, cung cấp các giải pháp và phân tích an ninh mạng tiên tiến nhất. Để nhận được tư vấn chuyên sâu hoặc hỗ trợ nhanh chóng, vui lòng liên hệ với chúng tôi qua email: info@unitas.vn hoặc Hotline: (+84) 939 586 168.