
Khi mọi người nghe đến từ “catalog” trong các cuộc thảo luận về dữ liệu, sự nhầm lẫn thường xuất hiện. Nguyên nhân là vì có hai công cụ hoàn toàn khác nhau nhưng lại cùng được gọi chung bằng một tên: business catalog như Collibra và Atlan, và technical catalog như Iceberg REST Catalog. Việc hiểu rõ mỗi loại catalog làm gì và chúng nên nằm ở đâu trong kiến trúc dữ liệu sẽ giúp tổ chức tránh được những sai lầm thiết kế tốn kém.
Business catalog làm gì
Business catalog tồn tại để giúp con người tìm kiếm, hiểu và tin tưởng dữ liệu trong toàn bộ tổ chức. Có thể hình dung chúng như một thư mục tìm kiếm, trả lời các câu hỏi như: tổ chức đang có những dữ liệu gì, ai là người sở hữu dữ liệu đó, một cột dữ liệu thực sự có ý nghĩa gì, hay một tập dữ liệu có được phê duyệt để sử dụng trong báo cáo tài chính hay không.
Các công cụ như Collibra và Atlan rất mạnh ở vai trò này. Chúng lưu trữ định nghĩa nghiệp vụ, theo dõi luồng dữ liệu, quản lý các chính sách quản trị và liên kết các tài sản dữ liệu với những nhóm chịu trách nhiệm. Một business analyst có thể sử dụng business catalog để khám phá các bộ dữ liệu khách hàng hiện có, hiểu cách chỉ số “giá trị vòng đời khách hàng” được tính toán, và xác nhận rằng một bảng dữ liệu đã được chứng nhận để sử dụng trong dashboard điều hành.
Business catalog bao phủ toàn bộ hệ sinh thái dữ liệu. Chúng có thể tham chiếu đến bảng trong data warehouse, file trong data lake, báo cáo trong công cụ BI và dữ liệu trong các ứng dụng SaaS bên thứ ba. Giá trị cốt lõi của business catalog nằm ở việc cung cấp một điểm truy cập duy nhất để mọi người trong tổ chức có thể tìm kiếm dữ liệu trên tất cả các hệ thống này.
Iceberg rest catalog làm gì
Iceberg REST Catalog phục vụ một mục đích hoàn toàn khác. Nó theo dõi trạng thái vật lý của các bảng Apache Iceberg để các công cụ truy vấn có thể đọc và ghi dữ liệu một cách chính xác.
Khi bạn tạo một bảng Iceberg, các file dữ liệu được lưu trữ trong object storage như Amazon S3 hoặc Google Cloud Storage. Tuy nhiên, công cụ truy vấn không chỉ cần biết rằng “dữ liệu nằm đâu đó trong bucket”. Nó cần biết schema hiện tại của bảng, file nào chứa dữ liệu đang hoạt động và file nào đã bị xóa, bảng được phân vùng như thế nào, và các snapshot nào tồn tại để phục vụ truy vấn time travel.
Iceberg REST Catalog lưu trữ các metadata kỹ thuật này. Khi Spark, Trino hoặc Flink truy vấn một bảng Iceberg, chúng sẽ truy vấn catalog trước để hiểu trạng thái hiện tại của bảng, sau đó truy cập trực tiếp vào object storage để đọc các file liên quan.
Vì sao sự khác biệt này quan trọng
Hai loại catalog này hoạt động ở các mức trừu tượng khác nhau và phục vụ những đối tượng người dùng khác nhau.
Business catalog hoạt động ở cấp độ tổ chức. Chúng giúp con người điều hướng dữ liệu bằng cách cung cấp ngữ cảnh vượt ra ngoài bất kỳ hệ thống lưu trữ đơn lẻ nào. Các khái niệm như “khách hàng đang hoạt động”, người phụ trách dữ liệu bán hàng, hay chính sách truy cập dữ liệu cá nhân đều trải rộng trên nhiều cơ sở dữ liệu, warehouse và data lake.
Iceberg REST Catalog hoạt động ở cấp độ lưu trữ. Nó theo dõi thực tế vật lý của các file trong object storage: những file Parquet nào tạo thành bảng, phiên bản schema áp dụng cho từng file, và cách xử lý các ghi đồng thời để tránh làm hỏng dữ liệu.
Vì sao việc nhúng iceberg rest catalog vào object storage là hợp lý
Với sự khác biệt này, việc nhúng Iceberg REST Catalog trực tiếp vào object storage là một lựa chọn kiến trúc tự nhiên vì nhiều lý do.
Thứ nhất, catalog và dữ liệu mà nó mô tả vốn đã nằm cùng một nơi. Bảng Iceberg là tập hợp các file trong object storage, còn metadata của catalog chỉ ra chính xác các file đó. Việc đặt chúng cùng nhau giúp giảm độ phức tạp vận hành và hạn chế các bước kết nối mạng không cần thiết.
Thứ hai, Iceberg REST Catalog có phạm vi trách nhiệm hẹp và rõ ràng. Nó chỉ quản lý các bảng trong một môi trường lưu trữ cụ thể. Phạm vi giới hạn này khiến nó rất phù hợp để được nhúng trực tiếp, vì trách nhiệm của catalog trùng khớp với ranh giới của hệ thống lưu trữ.
Thứ ba, nhiều tổ chức đang chuyển sang kiến trúc cloud-native, trong đó object storage đóng vai trò nền tảng cho phân tích dữ liệu. Việc nhúng Iceberg REST Catalog vào lớp này giúp object storage trở thành một nền tảng hoàn chỉnh hơn cho mô hình data lakehouse mà không buộc đội ngũ phải triển khai thêm hạ tầng riêng biệt.
Catalog của các catalog và sự xuất hiện của platform catalog
Khi các tổ chức áp dụng kiến trúc lakehouse, một lớp trung gian đã xuất hiện giữa technical catalog và business catalog. Platform catalog đảm nhiệm vai trò này bằng cách liên kết nhiều technical catalog thành một góc nhìn thống nhất trong từng hệ sinh thái.
Databricks Unity Catalog kết nối với các catalog bên ngoài như AWS Glue và Hive Metastore thông qua Lakehouse Federation. Apache Polaris cung cấp triển khai Iceberg REST mã nguồn mở với khả năng liên kết nhiều catalog. Snowflake Horizon thống nhất quản trị giữa các bảng Iceberg nội bộ và bên ngoài. AWS Glue Data Catalog đóng vai trò kho metadata trung tâm cho các dịch vụ phân tích trên AWS.
Những công cụ này giải quyết một vấn đề thực tế: data engineer không còn phải theo dõi bảng dữ liệu đang nằm trong catalog nào. Platform catalog cung cấp góc nhìn thống nhất, kiểm soát truy cập nhất quán và theo dõi lineage trên nhiều nguồn dữ liệu liên kết.
Tuy nhiên, platform catalog vẫn bị giới hạn trong phạm vi hệ sinh thái của chúng. Chúng không được thiết kế để quản lý dữ liệu trong CRM, lập chỉ mục báo cáo BI hay duy trì định nghĩa nghiệp vụ xuyên phòng ban. Chúng phục vụ người dùng kỹ thuật cần truy vấn dữ liệu, chứ không phải người dùng nghiệp vụ cần hiểu ý nghĩa của dữ liệu.
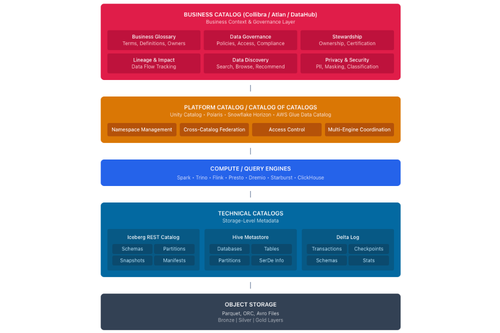
Ba lớp catalog trong tổ chức hiện đại
Chính vì vậy, nhiều tổ chức vận hành đồng thời ba lớp catalog:
Technical catalog như Iceberg REST đảm nhiệm việc quản lý trạng thái vật lý của bảng trong object storage, trả lời câu hỏi bảng dữ liệu hiện tại đang ở trạng thái nào.
Platform catalog như Unity Catalog, Polaris, Snowflake Horizon và AWS Glue liên kết các technical catalog và bổ sung kiểm soát quản trị, trả lời câu hỏi người dùng có thể truy cập bảng nào và theo những quy tắc gì.
Business catalog như Collibra và Atlan hoạt động ở cấp độ tổ chức, bao phủ nhiều nền tảng, trả lời câu hỏi dữ liệu nào tồn tại trong toàn bộ doanh nghiệp, dữ liệu đó có ý nghĩa gì và có đáng tin cậy hay không.
Mỗi lớp phục vụ một nhóm đối tượng khác nhau với phạm vi khác nhau. Hiểu rõ vai trò của từng lớp giúp doanh nghiệp thiết kế kiến trúc phát huy đúng thế mạnh của từng công cụ.
Kết nối các lớp catalog với nhau
Từ “catalog” xuất hiện xuyên suốt kiến trúc dữ liệu hiện đại, nhưng các công cụ phía sau thuật ngữ này phục vụ những mục đích hoàn toàn khác nhau. Technical catalog quản lý trạng thái vật lý của bảng cho công cụ truy vấn. Platform catalog liên kết các technical catalog và thực thi chính sách truy cập trong một hệ sinh thái. Business catalog cung cấp ngữ cảnh tổ chức, giúp con người tìm kiếm, hiểu và tin tưởng dữ liệu trên mọi hệ thống.
Các lớp này không cạnh tranh mà bổ trợ cho nhau. Điều quan trọng là đặt đúng catalog vào đúng vị trí. Technical catalog nên nằm gần lớp lưu trữ. Platform catalog nên liên kết trong phạm vi hệ sinh thái của mình. Business catalog nên nằm ở cấp độ tổ chức để kết nối toàn bộ nền tảng và hệ thống lưu trữ.
Khi không còn xem “catalog” là một khái niệm đơn lẻ mà nhìn nhận nó như các lớp chức năng khác nhau, các quyết định kiến trúc dữ liệu sẽ trở nên rõ ràng và hợp lý hơn.
Unitas cam kết đồng hành cùng doanh nghiệp, cung cấp các giải pháp và phân tích an ninh mạng tiên tiến nhất. Để nhận được tư vấn chuyên sâu hoặc hỗ trợ nhanh chóng, vui lòng liên hệ với chúng tôi qua email: info@unitas.vn hoặc Hotline: (+84) 939 586 168.




