

Khi hệ thống bình thường… cho đến khi mọi thứ bùng nổ
Khi dashboard vẫn xanh, CPU ổn định, tỷ lệ lỗi thấp, ta thường thấy hệ thống “ổn”. Tuy nhiên, ngay lúc cảnh báo bật lên, mọi thứ có thể sụp đổ. Metrics báo có sự bất thường, nhưng không chỉ ra rõ lý do, vị trí, hoặc nguyên nhân. Chỉ khi đó, logs mới là thứ cung cấp toàn bộ ngữ cảnh: ai gây ra sự cố, khi nào, và hành vi diễn ra ra sao.
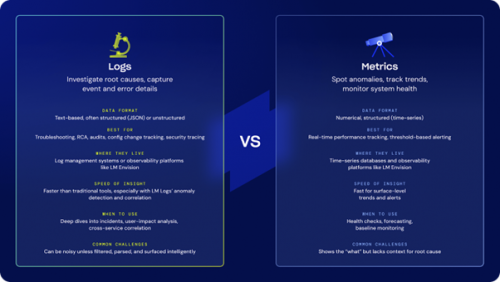
Metrics giúp bạn biết điều gì đang xảy ra. Logs giúp bạn hiểu tại sao. Cả hai kết hợp sẽ giúp bạn xử lý sự cố nhanh hơn và chủ động hơn trong việc ngăn chặn.
Phối hợp Logs và Metrics thế nào để đạt hiệu quả cao?
1. Nhận tín hiệu – Tìm câu chuyện
Metrics cảnh báo khi có vấn đề – ví dụ như tăng độ trễ API hay CPU lên cao. Lúc này, logs tương quan sẽ được tự động kéo về, cung cấp cái nhìn chi tiết về thời điểm, lỗi, hoặc sự kiện đã thay đổi. Không phải tìm kiếm thủ công, không phải truy vấn phức tạp.
2. Kết nối sự kiện trong môi trường phức tạp
Trong môi trường hybrid hoặc microservices, một sự cố ở nơi này có thể ảnh hưởng đến nhiều thành phần khác. Metrics phần nào cho thấy hậu quả, logs lại hé lộ nguyên nhân gốc – lỗi cấu hình, thay đổi code, hay dịch vụ bị ngắt kết nối.
Tích hợp metrics và logs trên cùng hệ thống giúp loại bỏ việc chuyển đổi giữa nhiều công cụ, giảm thiểu thời gian chậm trễ và sai sót khi xử lý sự cố.
3. Rút ngắn MTTR với quy trình hai bước
- Bước 1: Bắt đầu với metrics để nhanh chóng phát hiện vấn đề.
- Bước 2: Khám phá logs để xác định chi tiết khi nào, ở đâu, tại sao xảy ra sự cố.
Cơ chế tự động phân tích bất thường và lọc bỏ noise trong logs giúp bạn không phải “đào” qua hàng nghìn dòng dữ liệu hay chuyển trách nhiệm lên cấp cao hơn.
4. Chuẩn đoán nguyên nhân nhanh hơn, giảm thiểu khủng hoảng
Khi dịch vụ đình trệ hoặc người dùng không thể đăng nhập, bạn cần câu trả lời tức thì. Việc thống nhất metrics và logs giúp tiến hành phân tích nhanh, giảm thiểu việc “chạy tool”, tăng độ chính xác cảnh báo, và đẩy nhanh quá trình xử lý sự cố.
Quy trình xử lý sự cố theo bốn bước:
- Detection: Metrics cảnh báo đúng lúc, không chậm trễ.
- Triage: Logs và metrics cùng nhìn, không cần chuyển qua nhiều công cụ.
- Diagnosis: Logs thể hiện chi tiết sự kiện, thời gian, vị trí và nguồn cơn.
- Resolution: Xác định nguyên nhân gốc, đưa hệ thống trở lại hoạt động nhanh.
Tại sao Observability Tập Trung Lại Quan Trọng?
Khi metrics và logs phân tán ở nhiều công cụ, bạn sẽ mất thời gian ghép nối ngữ cảnh, kéo dài thời gian sự cố và làm SLA bị ảnh hưởng. Observability tập trung giúp:
- Loại bỏ lỗ hổng ngữ cảnh giữa các hệ thống.
- Giảm thời gian chuyển đổi giữa dashboard và logs.
- Giảm rủi ro do mất thông tin trong quá trình điều tra.
Một Nền Tảng, Quan Sát Toàn Diện
Bạn không nên phải vật lộn với công cụ của mình khi từng giây đều quan trọng. Đó là lý do chúng tôi xây dựng LogicMonitor (LM) Envision — một nền tảng hợp nhất log và metric trong một giao diện thời gian thực duy nhất.
Với LM Envision, đội ngũ của bạn có thể:
- Tương quan metric và log ngay lập tức
- Phát hiện bất thường nhanh hơn với insight do AI hỗ trợ
- Rút ngắn thời gian tìm nguyên nhân gốc rễ và ngăn chặn sự cố trước khi lan rộng
Và đây không chỉ là lý thuyết. Sau khi triển khai LM Envision, Schneider Electric đã rút ngắn MTTR và tăng độ chính xác cảnh báo lên 40%, tất cả nhờ cung cấp cho đội ngũ quyền truy cập nhanh hơn vào toàn bộ bối cảnh phía sau mỗi cảnh báo.
Giải pháp cung cấp thông tin của hãng:
![]()
Unitas là nhà phân phối ủy quyền tại Việt Nam của các công ty công nghệ nghệ thuật: Commvault, ExaGrid, VergeIO, Nexsan, DDN, Tintri, MinIO, LogicMonitor, Netgain, Kela, UltraRed, Sling, Quokka, An toàn, Hackuity, Cyabra, Cymetrics, ThreatDown, F-Secure, OutSystems, Micas Networks ….
Liên hệ Unitas ngay hôm nay để được tư vấn chi tiết!




