

Giới thiệu
Hầu hết các tổ chức CNTT đều dành nhiều thời gian suy nghĩ và nghiên cứu để lựa chọn một ứng dụng backup. Tuy nhiên, phần lớn cũng cho rằng bạn có thể chỉ cần đặt bất kỳ loại lưu trữ nào phía sau ứng dụng backup, và nó sẽ hoạt động ngay lập tức.
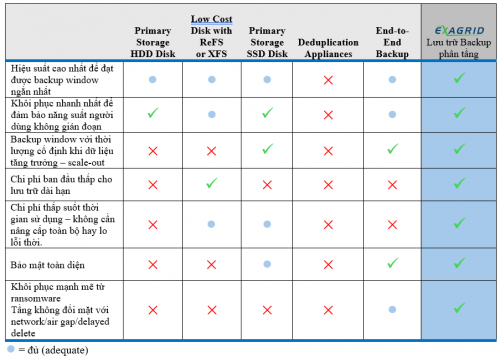
Việc chọn sai lưu trữ backup có thể ảnh hưởng đến:
- Hiệu suất backup và thời gian backup window thực tế
- Hiệu suất khôi phục và tác động đến người dùng
- Liệu backup window có giữ được thời lượng cố định khi dữ liệu tăng lên hay không
- Mất bao nhiêu thời gian để quản lý các bản backup
- Mức độ dễ bị tấn công bảo mật hoặc ransomware của loại lưu trữ
- Tổng chi phí theo thời gian.
Trong lưu trữ chính (primary storage), bạn chỉ cần mua số terabyte hoặc petabyte khả dụng mà bạn cần, bao gồm một phần tăng trưởng nhất định. Tuy nhiên, không giống như lưu trữ chính, lưu trữ backup có những đặc điểm độc đáo như:
- Các tác vụ backup lớn
- Backup rotation: incrementals, differentials, fulls, synthetic fulls, reconstituted fulls, v.v.
- Khử trùng lặp dữ liệu (data deduplication), ảnh hưởng đến hiệu suất, dung lượng lưu trữ và sizing hệ thống, v.v.
Lưu trữ backup phức tạp hơn nhiều. Trong khi các ứng dụng backup thường là tâm điểm chú ý, lưu trữ backup lại thường bị bỏ qua, dẫn đến hiệu suất kém và chi phí quá mức cho lưu trữ trong môi trường backup. Ngoài ra, tầm quan trọng của việc sử dụng lưu trữ backup như một phần quan trọng trong quá trình khôi phục, đặc biệt là sau một cuộc tấn công ransomware, cũng cần được chú ý. Việc chuẩn bị cho quá trình khôi phục từ một thảm họa tại site cũng là một phần quan trọng trong vấn đề này.
- File system lưu trữ có được tối ưu hóa tối đa cho:
- các file tiêu chuẩn không?
- giao dịch cơ sở dữ liệu không?
- HAY thực sự được tối ưu hóa cho các tác vụ backup lớn?
- Lưu trữ có được tích hợp với các giao thức tiên tiến được thiết kế đặc biệt cho các tác vụ backup lớn như Veritas NetBackup OST, Veeam Data Mover, v.v. không?
- Lưu trữ backup của bạn có thể thực hiện đồng thời nhiều tác vụ (các tác vụ chạy song song) không?
- Lưu trữ backup là “scale-up” (mở rộng lên), khiến backup window tăng theo dữ liệu, hay là “scale-out” (mở rộng ra), giữ backup window cố định khi dữ liệu tăng?
- Làm thế nào để đảm bảo lưu trữ được sizing chính xác cho:
- backup rotation
- thời gian lưu giữ backup: hàng ngày, hàng tuần, hàng tháng, hàng năm
- replicate chéo cho nhiều site
- DR (Disaster Recovery) site thứ 2
- tăng trưởng dữ liệu trong 3 đến 5 năm tới
- liệu ứng dụng backup hay lưu trữ backup có khử trùng lặp dữ liệu không
- Tác động đến hiệu suất như thế nào (vì khử trùng lặp đòi hỏi nhiều tài nguyên tính toán)?
- Tỷ lệ khử trùng lặp và mức tiết kiệm lưu trữ là bao nhiêu khi mỗi nhà cung cấp khác nhau?
- Bao nhiêu dữ liệu được mã hóa hoặc nén, vì khử trùng lặp phía mục tiêu sẽ không mang lại thêm hiệu quả khử trùng lặp nào?
Yêu cầu cốt lõi

Lưu trữ chính – HDD
Lưu trữ chính được thiết kế cho các file của người dùng chứ không phải cho backup. Nó thường chậm đối với các tác vụ backup lớn, vì đây chỉ là lưu trữ đơn thuần mà không phải là một thiết bị/máy chủ tích hợp. HDD lưu trữ chính không thể chạy các giao thức vận chuyển tiên tiến của ứng dụng backup và trở nên rất đắt đỏ cực kì nhanh chóng do không có khả năng khử trùng lặp dữ liệu bổ sung ngoài ứng dụng backup. Tỷ lệ khử trùng lặp của ứng dụng backup thường là 1:1, 2:1, 3:1, tối đa 5:1. Điều này giúp tiết kiệm một phần dung lượng lưu trữ, nhưng không tối ưu hóa tối đa, dẫn đến chi phí lưu trữ cao cho việc lưu giữ dài hạn.
Các yếu tố cần xem xét:
- Không được tối ưu hóa cho hiệu suất backup (file system, giao thức backup tiên tiến, đồng thời thực hiện nhiều tác vụ, v.v.). Điều này dẫn đến backup window dài hơn và tăng dần theo thời gian.
- Khôi phục sẽ nhanh như tốc độ đĩa nếu dữ liệu không bị khử trùng lặp bởi ứng dụng backup. Nếu dữ liệu đã bị khử trùng lặp bởi ứng dụng backup, các khối dữ liệu đã khử trùng lặp phải được ghép lại hoặc “tái hấp thụ”, điều này làm chậm quá trình khôi phục.
- Lưu trữ thường không phải là loại scale-out, nên backup window tăng lên khi dữ liệu tăng, khiến bạn phải liên tục chạy theo một backup window ngày càng mở rộng.
- Trở nên rất đắt đỏ với việc lưu giữ dài hạn hơn 6 bản sao. Lưu trữ thường được sizing nhỏ hơn thực tế vì các nhà cung cấp không biết cách sizing cho backup, bao gồm backup rotation, tăng trưởng dữ liệu, chính sách lưu giữ, replicate chéo, v.v. Luôn so sánh kỹ lưỡng khi sizing, vì lưu trữ thường được sizing nhỏ để trông rẻ hơn. (Bạn có thể phải mua thêm lưu trữ sau 6 đến 9 tháng.)
- Lưu trữ đối mặt với mạng và dễ bị tấn công bảo mật.
- Lưu trữ thường bị ngừng sản xuất, buộc bạn phải mua thiết bị khác. (Lỗi thời sản phẩm)
- Chi phí theo thời gian lớn hơn nhiều so với dự đoán, vì sizing ban đầu thường không đủ.
- Quản lý các silo lưu trữ chính đòi hỏi thời gian của nhân viên CNTT.
- Các tổ chức hỗ trợ không hiểu về lưu trữ backup, dẫn đến tình trạng đổ lỗi qua lại giữa nhà cung cấp backup và nhà cung cấp thiết bị lưu trữ.
Máy chủ đĩa chi phí thấp – HDD
Máy chủ lưu trữ chi phí thấp được thiết kế cho các file của người dùng chứ không phải cho backup. Nó thường chậm đối với các tác vụ backup lớn, vì đây chỉ là lưu trữ đơn thuần mà không phải là một thiết bị/máy chủ tích hợp. Máy chủ đĩa chi phí thấp không thể chạy các giao thức vận chuyển tiên tiến của ứng dụng backup và trở nên rất đắt đỏ cực kì nhanh chóng do không có khả năng khử trùng lặp dữ liệu bổ sung ngoài ứng dụng backup. Tỷ lệ khử trùng lặp của ứng dụng backup thường là 1:1, 2:1, 3:1, tối đa 5:1. Điều này giúp tiết kiệm một phần dung lượng lưu trữ, nhưng không tối ưu hóa tối đa. Ngoài ra, lưu trữ chi phí thấp thường sử dụng các ổ HDD dung lượng lớn với một bộ điều khiển đầu cuối (front-end controller) duy nhất để giảm chi phí và giá bán. Vì các ổ đĩa có dung lượng lớn hơn, số lượng trục quay (spindle) ít hơn, dẫn đến ảnh hưởng lớn đến hiệu suất. Ví dụ, nếu một máy chủ có 10 ổ 4TB, sẽ có 10 trục quay để ghi đồng thời. Nếu máy chủ có 4 ổ 10TB, chỉ có 4 trục quay để ghi. Hơn nữa, bộ điều khiển đầu cuối là một nút thắt cổ chai. Nếu bạn xem xét tốc độ nhập liệu định mức và chia cho số TB để tính hiệu suất trên mỗi TB, nó rất chậm đối với backup.
Các yếu tố cần xem xét:
- Không được tối ưu hóa cho hiệu suất backup (file system, giao thức backup tiên tiến, đồng thời thực hiện nhiều tác vụ, v.v.). Điều này dẫn đến backup window dài hơn.
- Số lượng trục quay (spindle) thấp với bộ điều khiển đơn là nút thắt cổ chai.
- Khôi phục sẽ chậm hơn so với đĩa lưu trữ chính nếu dữ liệu không bị khử trùng lặp bởi ứng dụng backup do nút thắt từ trục quay và bộ điều khiển. Nếu dữ liệu đã bị khử trùng lặp bởi ứng dụng backup, các khối dữ liệu khử trùng lặp phải được ghép lại hoặc “rehydrate”, điều này làm chậm quá trình khôi phục.
- Lưu trữ không phải là loại scale-out, nên backup window tăng lên khi dữ liệu tăng, khiến bạn phải liên tục chạy theo một backup window ngày càng mở rộng.
- Vì chi phí thấp, nó giúp cải thiện kinh tế ở mức độ nào đó nhưng vẫn trở nên đắt đỏ tại một điểm lưu giữ nhất định. Lưu trữ thường được sizing nhỏ hơn thực tế vì các nhà cung cấp không biết cách sizing cho backup, bao gồm xoay vòng backup, tăng trưởng dữ liệu, chính sách lưu giữ, replicate chéo, v.v. Luôn so sánh kỹ lưỡng khi sizing, vì các hệ thống sizing nhỏ thường trông rẻ hơn. (Bạn có thể phải mua thêm lưu trữ sau 6 đến 9 tháng.)
- Lưu trữ đối mặt với mạng và dễ bị tấn công bảo mật.
- Lưu trữ thường bị ngừng sản xuất, buộc bạn phải mua thiết bị khác. (Lỗi thời sản phẩm)
- Chi phí theo thời gian lớn hơn nhiều so với dự đoán, vì sizing ban đầu thường không đủ.
- Quản lý các silo lưu trữ chính đòi hỏi thời gian của nhân viên CNTT.
- Bạn trả càng ít, mức độ hỗ trợ càng thấp. Các tổ chức hỗ trợ không hiểu về lưu trữ backup, dẫn đến tình trạng đổ lỗi qua lại giữa nhà cung cấp backup và nhà cung cấp lưu trữ.
Lưu trữ Solid State – SSD
Lưu trữ Solid State (SSD) được thiết kế cho các giao dịch cơ sở dữ liệu. Nó thường chậm hơn đối với các tác vụ backup lớn, vì đây chỉ là lưu trữ đơn thuần mà không phải là một thiết bị/máy chủ tích hợp. Lưu trữ Solid State không thể chạy các giao thức vận chuyển tiên tiến của ứng dụng backup và trở nên rất đắt đỏ cực kì nhanh chóng do không có khả năng khử trùng lặp dữ liệu bổ sung ngoài ứng dụng backup. Tỷ lệ khử trùng lặp của ứng dụng backup thường là 1:1, 2:1, 3:1, tối đa 5:1. Điều này giúp tiết kiệm một phần dung lượng lưu trữ, nhưng không tối ưu hóa tối đa. Cuối cùng, SSD thường có chi phí cao gấp 5 lần trên mỗi TB so với ổ đĩa HDD tiêu chuẩn.
Các yếu tố cần xem xét:
- Không được tối ưu hóa cho hiệu suất backup (file system, giao thức backup tiên tiến, đồng thời thực hiện nhiều tác vụ, v.v.). Điều này dẫn đến backup window dài hơn. Điều này nghe có vẻ trái ngược với SSD, vì vậy hãy kiểm tra trước khi mua, và bạn sẽ thấy rằng file system cần được tối ưu hóa cho các file backup lớn.
- Khôi phục sẽ nhanh hơn so với ổ đĩa HDD nếu dữ liệu không bị khử trùng lặp bởi ứng dụng backup. Nếu dữ liệu đã bị khử trùng lặp bởi ứng dụng backup, các khối dữ liệu khử trùng lặp phải được ghép lại hoặc “rehydrate”, điều này làm chậm quá trình khôi phục nhưng vẫn sẽ nhanh hơn so với ổ đĩa HDD.
- Các hệ thống này thường là loại scale-out, tuy nhiên tài nguyên tính toán phải tăng trưởng cùng tốc độ với dữ liệu, nếu không backup window sẽ tăng lên khi dữ liệu tăng, khiến bạn phải liên tục chạy theo một backup window ngày càng mở rộng.
- Cực kỳ đắt đỏ với việc lưu giữ dài hạn vì SSD thường đắt gấp 5 lần so với HDD. SSD cực kỳ tốn kém cho lưu trữ backup. Lưu trữ thường được sizing nhỏ hơn thực tế vì các nhà cung cấp không biết cách sizing cho backup, bao gồm backup rotation, tăng trưởng dữ liệu, chính sách lưu giữ, replicate chéo, v.v. Luôn so sánh kỹ lưỡng khi sizing, vì các hệ thống sizing nhỏ thường trông rẻ hơn. (Bạn có thể phải mua thêm lưu trữ sau 6 đến 9 tháng.) SSD có thể trông gần với giá HDD nhưng bạn có thể không mua đủ dung lượng cần thiết.
- Lưu trữ đối mặt với mạng và dễ bị tấn công bảo mật. Cần mua thêm lưu trữ và công cụ bảo mật, điều này càng làm tăng chi phí.
- Chi phí theo thời gian lớn hơn nhiều so với dự đoán, vì sizing ban đầu thường không đủ.
- Các tổ chức hỗ trợ không hiểu về backup, dẫn đến tình trạng đổ lỗi qua lại giữa nhà cung cấp backup và nhà cung cấp lưu trữ.
Microsoft ReFS và Linux XFS
Đối với một tổ chức sử dụng ReFS và XFS, họ sử dụng tính năng sao chép khối (block cloning), có thể tăng gấp đôi tỷ lệ khử trùng lặp từ 2:1 lên 4:1. Kết quả là, điều này sẽ giảm 50% dung lượng lưu trữ cần thiết. Để giảm chi phí lưu trữ backup, các phòng ban CNTT sẽ kết hợp máy chủ đĩa chi phí thấp hoặc lưu trữ SSD với ReFS hoặc Linux XFS. Điều này hoạt động khá tốt cho các doanh nghiệp nhỏ không có nhiều dữ liệu, không có tốc độ tăng trưởng dữ liệu lớn và không yêu cầu cao về hiệu suất. Tuy nhiên, đối với các tổ chức lớn hơn, từ 50TB đến petabyte, tác động lên backup là rất đáng kể.
Các yếu tố cần xem xét:
- Có tất cả các thách thức của máy chủ đĩa chi phí thấp hoặc SSD đã được mô tả trước đó trong tài liệu này.
- Ngoài ra, ReFS và XFS còn gây ảnh hưởng thêm đến hiệu suất, vì vậy hiệu suất sẽ thấp hơn so với file system đĩa gốc.
- Không mở rộng tốt vì ReFS được thiết kế cho các cửa hàng CNTT nhỏ hơn.
- Đòi hỏi nhiều thời gian quản lý, đặc biệt là với Linux XFS.
- Phù hợp cho các cửa hàng CNTT nhỏ với dung lượng 30TB hoặc ít hơn, có thể không tốt cho các cửa hàng CNTT từ 30TB đến 50TB, và không phải là giải pháp khả thi cho thị trường trung cao cấp, doanh nghiệp nhỏ, doanh nghiệp vừa và doanh nghiệp lớn.
Thiết bị khử trùng lặp inline (Inline Deduplication Appliances)
Các thiết bị khử trùng lặp inline có khả năng khử trùng lặp dữ liệu tiên tiến và thường hiệu quả hơn từ 4 đến 10 lần so với khử trùng lặp trong các ứng dụng backup, giúp giảm đáng kể dung lượng lưu trữ backup và chi phí lưu trữ cho việc lưu giữ dài hạn. Tuy nhiên, các thiết bị này thực hiện khử trùng lặp dữ liệu trên đường truyền đến đĩa, điều này làm chậm quá trình backup đáng kể, xuống khoảng 1/6 tốc độ của đĩa. Họ triển khai phần mềm chạy trên máy chủ media server/agent để thực hiện một phần công việc trên các máy chủ backup, nhưng điều đó vẫn chỉ đạt hiệu suất khoảng 1/3 tốc độ của đĩa, và code của họ trên media server/agent chịu ảnh hưởng hiệu suất vì tài nguyên tính toán được sử dụng cho công việc khử trùng lặp trước. Vì khử trùng lặp được thực hiện inline, tất cả dữ liệu được lưu trữ dưới dạng các khối khử trùng lặp và phải được ghép lại (rehydrate) cho mỗi yêu cầu. Tốc độ khôi phục chỉ bằng khoảng 1/20 so với hiệu suất khôi phục của một file không khử trùng lặp trên đĩa tiêu chuẩn. Ngoài ra, các giải pháp này là loại scale-up, nên khi dữ liệu tăng lên, không có thêm tài nguyên bộ nhớ, tính toán và mạng được bổ sung, dẫn đến backup window ngày càng mở rộng. Kết quả là cách tiếp cận thế hệ đầu tiên này tiết kiệm dung lượng lưu trữ nhưng đánh đổi bằng hiệu suất backup, hiệu suất khôi phục và khả năng mở rộng. Bạn phải mất nhiều để giành được ít.
Các yếu tố cần xem xét:
- Hiệu suất chậm vì khử trùng lặp inline đòi hỏi nhiều tài nguyên tính toán. Ngay cả với phần mềm khử trùng lặp chạy trên media server, hiệu suất vẫn không đủ. Ngoài ra, không phải tất cả đều hỗ trợ đồng thời thực hiện nhiều tác vụ cho các công việc backup song song. Các thiết bị khử trùng lặp inline tiết kiệm chi phí lưu trữ nhưng là cách tiếp cận chậm nhất về hiệu suất nhập liệu.
- Khôi phục cực kỳ chậm, vì dữ liệu phải được ghép lại hoặc rehydrate cho mỗi yêu cầu. Việc khởi động VM có thể mất một giờ thay vì vài phút.
- Các giải pháp này không phải là loại scale-out, nên backup window tăng lên khi dữ liệu tăng, khiến bạn phải liên tục chạy theo một backup window ngày càng mở rộng. Điều này dẫn đến các nâng cấp toàn diện (forklift upgrades) tốn kém và gây gián đoạn.
- Lưu trữ backup đối mặt với mạng và rất dễ bị tấn công bảo mật. Bạn phải bổ sung thêm lưu trữ và phần mềm để tăng cường bảo mật, điều này gần như tăng gấp đôi chi phí.
- Lưu trữ thường bị ngừng sản xuất, buộc bạn phải mua thiết bị khác. (Lỗi thời sản phẩm)
- Chi phí theo thời gian lớn hơn nhiều so với dự đoán, vì sizing ban đầu thường không đủ. Các nhà cung cấp thường sizing nhỏ để giảm giá khởi điểm.
- Các tổ chức hỗ trợ không hiểu về lưu trữ backup, dẫn đến tình trạng đổ lỗi qua lại giữa nhà cung cấp backup và nhà cung cấp lưu trữ.
Giải pháp từ ứng dụng Backup đến lưu trữ Backup toàn diện (End-to-end Backup Application to Backup Storage Solutions)
Trong nhiều thập kỷ, công nghệ CNTT dao động giữa các hệ thống phân tán và các giải pháp tất-cả-trong-một, rồi lại quay về hệ thống phân tán. Với các giải pháp backup toàn diện, bạn đang đặt cược rằng nhà cung cấp có sản phẩm “tốt nhất trong ngành” cho cả ứng dụng backup và lưu trữ backup. Điều này hiếm khi đúng trong lĩnh vực backup. Nếu bạn quyết định thay đổi lưu trữ backup, bạn không thể làm điều đó và giờ đây bạn bị khóa vào một giải pháp backup không đủ tốt và rất đắt đỏ. Nhiều giải pháp toàn diện che giấu chi phí thực sự bằng cách khuyến nghị bạn giữ dữ liệu từ 2 đến 4 tuần onsite và sau đó lưu tất cả dữ liệu dài hạn trên cloud. Các tổ chức CNTT thấy chi phí thấp cho hệ thống onsite nhưng không biết về chi phí cloud trong 36 đến 60 tháng tới. Sau đó, khi họ nhận được hóa đơn cloud sau khoảng 9 tháng, họ mới thấy chi phí thực sự của lưu trữ và giờ đây họ đã bị KHÓA CHẶT.
Các yếu tố cần xem xét:
- Hiệu suất backup chậm vì họ thực hiện khử trùng lặp dữ liệu inline, nén và mã hóa tất cả trong phần mềm, làm chậm quá trình backup.
- Khôi phục chậm vì họ phải rehydrate các khối dữ liệu khử trùng lặp cho mỗi yêu cầu.
- Chúng là loại scale-out, tuy nhiên rất đắt đỏ vì chúng sử dụng mã hóa xóa (erasure coding) để đạt được tính dư thừa (redundancy), điều này làm tăng chi phí đáng kể.
- Trở nên rất đắt đỏ với việc lưu giữ dài hạn vì tỷ lệ khử trùng lặp chỉ từ 3:1 đến 5:1, nên chúng sử dụng nhiều dung lượng đĩa. Chúng thường được sizing nhỏ hơn thực tế vì các nhà cung cấp không biết cách sizing cho backup, bao gồm backup rotation, tăng trưởng dữ liệu, chính sách lưu giữ, replicate chéo, v.v. Ngoài ra, không có cách dễ dàng để xác định chi phí hàng tháng trên cloud cho lưu trữ dài hạn. Luôn so sánh kỹ lưỡng khi sizing, vì các hệ thống sizing nhỏ thường trông rẻ hơn. Tuy nhiên, rất có thể bạn sẽ phải mua thêm lưu trữ sau 6 đến 9 tháng.
- Họ quảng bá các đối tượng dữ liệu bất biến (immutable data objects) để khôi phục sau ransomware, tuy nhiên điều đó giả định rằng không có cách nào để truy cập vào các đối tượng dữ liệu bất biến này. Họ không có tầng không đối mặt với mạng (tiered air gap).
- Thường thì họ yêu cầu bạn mua phần cứng từ một nhà cung cấp riêng biệt.
- Các tổ chức hỗ trợ không hiểu về lưu trữ backup, dẫn đến tình trạng đổ lỗi qua lại giữa nhà cung cấp backup và nhà cung cấp lưu trữ.
Lưu trữ Backup Phân tầng ExaGrid (ExaGrid Tiered Backup Storage)
Lưu trữ Backup Phân tầng ExaGrid được thiết kế dành riêng cho backup. Nó xem xét đến hiệu suất backup, hiệu suất khôi phục, backup window cố định khi dữ liệu tăng trưởng, tầng không đối mặt với mạng để đảm bảo bảo mật, chi phí ban đầu, chi phí theo thời gian và hỗ trợ hiểu biết cả về ứng dụng backup lẫn lưu trữ backup.
Các yếu tố cần xem xét:
- Landing Zone phía trước độc nhất. Backup ghi trực tiếp vào đĩa mà không có khử trùng lặp inline làm chậm quá trình. Hiệu suất nhanh nhờ:
- Không có khử trùng lặp inline.
- File system được tối ưu hóa cho các tác vụ backup lớn.
- Sử dụng các giao thức tiên tiến để tăng hiệu suất như Veeam Data Mover hoặc Veritas NetBackup OST, v.v.
- Sử dụng đồng thời nhiều tác vụ (job concurrency) cho các công việc backup song song.
- Sử dụng chức năng tích hợp của ứng dụng backup để cân bằng tải công việc phía trước (Veeam SOBR, NetBackup Single Storage Disk Pool, Commvault Spill & Fill, Oracle RMAN Channels, HYCU Scale-out, v.v.).
- Mã hóa dữ liệu tại chỗ ở mức ổ đĩa (mất vài nano giây).
- Thông thường, nhanh gấp 2 lần so với SSD và nhanh gấp 3 đến 5 lần so với các thiết bị khử trùng lặp inline.
- Khôi phục nhanh như tốc độ đĩa, vì dữ liệu nằm trong Landing Zone ở định dạng gốc của ứng dụng backup, sẵn sàng để khôi phục.
- Mở rộng theo kiểu scale-out, nơi tài nguyên tính toán được thêm vào cùng với dung lượng, hệ thống mở rộng tuyến tính giữ backup window cố định khi dữ liệu tăng trưởng.
- Dữ liệu được khử trùng lặp từ Landing Zone vào tầng kho lưu trữ (Repository Tier) không đối mặt với mạng, nơi lưu giữ bản sao mới nhất của dữ liệu trong Landing Zone và tất cả dữ liệu lưu giữ dài hạn ở định dạng khử trùng lặp cao để giảm đáng kể yêu cầu lưu trữ và chi phí liên quan. ExaGrid cho phép Veeam và Commvault giữ chức năng khử trùng lặp dữ liệu gốc của họ ở trạng thái “on” và ExaGrid sẽ tiếp tục khử trùng lặp thêm dữ liệu đó.
- Tất cả dữ liệu được lưu trữ ở định dạng khử trùng lặp trong tầng kho lưu trữ không đối mặt với mạng mà các tác nhân đe dọa không thể thấy hoặc truy cập. Hệ thống áp dụng chính sách xóa trễ (delayed delete) để đảm bảo dữ liệu bị xóa trong Landing Zone không bị xóa ngay lập tức trong kho lưu trữ. Ngoài ra, hệ thống có thể chịu được việc nhập dữ liệu mã hóa vì tất cả các đối tượng dữ liệu trong kho lưu trữ trước đó là bất biến (immutable), nghĩa là chúng không bị thay đổi, xóa hoặc chỉnh sửa, bảo vệ bản backup gần nhất và tất cả các điểm lưu giữ.
- Không có tình trạng lỗi thời sản phẩm theo kế hoạch, vì ExaGrid cho phép kết hợp và khớp bất kỳ thiết bị nào có tuổi đời hoặc kích thước bất kì nào trong cùng một hệ thống. Vì vậy, ngay cả khi một mẫu không còn được bán, nó vẫn có thể được sử dụng với các mẫu hiện tại.
- Sizing cho backup cực kỳ phức tạp vì không giống như lưu trữ chính, có hàng tá yếu tố ảnh hưởng như rotation, lưu giữ, loại dữ liệu, v.v. ExaGrid có các công cụ sizing chi tiết và tự hào cam kết không sizing thiếu.
- Hệ thống của ExaGrid được thiết kế để dễ sử dụng. Khách hàng thường xuyên nói rằng họ dành ít thời gian nhất cho ExaGrid.
- ExaGrid chỉ định một kỹ sư hỗ trợ cấp 2 cho mỗi tài khoản khách hàng, để người phụ trách CNTT luôn làm việc với cùng một kỹ sư hỗ trợ cấp cao. Bạn không bị chuyển vòng quanh và không phải lặp lại các vấn đề nhiều lần. Các kỹ sư hỗ trợ cấp 2 của ExaGrid là chuyên gia về ứng dụng backup, mạng và Lưu trữ Backup Phân tầng ExaGrid.
Tổng kết
Lưu trữ backup rất phức tạp, và việc đưa ra quyết định mua backup sai lầm là điều dễ xảy ra.
ExaGrid khuyến nghị bạn:
- Dành thời gian để thực sự lắng nghe, tìm hiểu tất cả các chi tiết và đặc điểm của tất cả các giải pháp.
- Nói chuyện với ít nhất 3 đến 5 tài khoản tham chiếu đang sử dụng giải pháp, đảm bảo rằng chỉ có bạn và khách hàng tham gia, và nhà cung cấp không có mặt trong cuộc gọi. Hãy nhớ rằng, ai cũng có những câu chuyện thành công của khách hàng, hãy nói chuyện trực tiếp với khách hàng.
- Kiểm tra, kiểm tra, kiểm tra. Có rất nhiều lời quảng cáo thổi phồng và nhiều nhân viên bán hàng kể những câu chuyện thú vị. Không gì vượt qua được việc thử nghiệm song song và tự mình chứng kiến hiệu suất nhập liệu, hiệu suất khôi phục và khả năng mở rộng. Ngoài ra, hãy thực hiện một cuộc tấn công bảo mật giả lập và xem hệ thống nào vẫn trụ vững.
- Luôn luôn kiểm tra kỹ, kiểm tra lại và kiểm tra lần nữa về sizing. Có hàng ngàn câu chuyện mà khách hàng đã mua dung lượng cho 3 năm tăng trưởng dữ liệu ngay từ đầu, nhưng chỉ sau 9 tháng, họ đã chạm giới hạn và phải mua thêm dung lượng, khiến chi phí dài hạn cao hơn nhiều so với kỳ vọng hoặc tưởng tượng.
Thông tin về hãng cung cấp giải pháp

Unitas là nhà phân phối ủy quyền tại Việt Nam của các hãng công nghệ lớn của thế giới: Commvault, ExaGrid, VergeIO, Nexsan, DDN, Tintri, MinIO, LogicMonitor, Netgain, Kela, UltraRed, Quokka, Safous, Hackuity, Cyabra, Cymetrics, ThreatDown, F-Secure, OutSystems, Micas Networks …




