

Tổng quan
Các quy trình AI và phân tích dữ liệu hiện đại hiếm khi chỉ tồn tại trong một môi trường duy nhất. Dữ liệu có thể nằm tại chỗ (on-premises), trong các đám mây riêng hoặc trên nhiều nền tảng đám mây công cộng. Việc xử lý và tính toán được triển khai ở nơi tối ưu nhất về chi phí, hiệu năng, độ tươi mới của dữ liệu hoặc yêu cầu tuân thủ. Thách thức lớn nhất luôn là làm thế nào để các môi trường phân tán này phối hợp hiệu quả với nhau mà không tạo ra gánh nặng vận hành, rủi ro bảo mật hoặc chi phí phát sinh do phải sao chép dữ liệu.
Databricks đã khẳng định vị thế là một trong những nền tảng hàng đầu cho các khối lượng công việc AI/ML trên đám mây, liên tục được Gartner xếp hạng là Leader trong Magic Quadrant cho Nền tảng Khoa học Dữ liệu và Machine Learning trong bốn năm liên tiếp, cũng như trong Magic Quadrant cho Hệ thống Quản lý Cơ sở Dữ liệu Đám mây trong năm năm liền. Tuy nhiên, với nhiều doanh nghiệp, dữ liệu phục vụ cho các khối lượng công việc này vẫn nằm tại chỗ, do các yêu cầu về tuân thủ pháp lý, chủ quyền dữ liệu, tối ưu chi phí, hoặc đơn giản là vì đó là nơi dữ liệu được tạo ra.
Hiện nay, hầu hết các tổ chức giải quyết khoảng cách này bằng cách xây dựng các pipeline tùy chỉnh để sao chép, đồng bộ và di chuyển dữ liệu giữa môi trường on-premises và đám mây. Cách tiếp cận này tuy hiệu quả về mặt kỹ thuật nhưng lại làm gia tăng chi phí và độ phức tạp trong vận hành.
Một cách tiếp cận tốt hơn
Bằng cách tích hợp Delta Sharing trực tiếp vào hệ thống object storage tại chỗ, các tổ chức có thể biến dữ liệu on-premises trở thành một thành phần “hạng nhất” trong các quy trình AI/ML và phân tích trên đám mây, mà không cần bổ sung hạ tầng hay sao chép dữ liệu.
Thực trạng hiện nay của Delta Sharing
Delta Sharing là một giao thức mở (open protocol), hay REST API, cho phép chia sẻ dữ liệu theo thời gian thực một cách an toàn. Giao thức này được phát triển trong khuôn khổ dự án Delta Lake dưới sự bảo trợ của Linux Foundation. Delta Sharing cho phép nhà cung cấp dữ liệu chia sẻ các bảng dữ liệu để bên nhận có thể truy vấn trực tiếp tại chỗ, bằng các công cụ mà họ lựa chọn.
Mặc dù bắt nguồn từ dự án Delta Lake, Delta Sharing không phụ thuộc vào định dạng dữ liệu cụ thể. Giao thức này có thể công bố các bảng được lưu trữ dưới nhiều định dạng lakehouse khác nhau, bao gồm Delta Lake và Apache Iceberg. Delta Sharing được thiết kế ở chế độ chỉ đọc, phù hợp với các kịch bản yêu cầu cao về tính toàn vẹn dữ liệu.
Hệ sinh thái công cụ hỗ trợ Delta Sharing khá rộng. Ngoài Databricks, nhiều nền tảng khác như Apache Spark, Trino, Power BI, Tableau, và Python với pandas cũng đã hỗ trợ giao thức này. Tính mở này là một trong những điểm mạnh cốt lõi của Delta Sharing: nhà cung cấp dữ liệu chỉ cần chia sẻ một lần, trong khi người tiêu dùng dữ liệu có thể sử dụng công cụ quen thuộc của họ.
Do Delta Sharing hoạt động ở cấp giao thức thay vì cấp định dạng lưu trữ, các tổ chức có thể chia sẻ bảng dữ liệu bất kể họ đang sử dụng Delta Lake, Apache Iceberg hay kết hợp cả hai. Điều này đặc biệt quan trọng đối với các doanh nghiệp lớn, nơi mỗi nhóm có thể chuẩn hóa theo các định dạng khác nhau hoặc đang trong quá trình chuyển đổi.
Tuy nhiên, trong thực tế, việc triển khai Delta Sharing hiện nay thường yêu cầu một máy chủ Delta Sharing độc lập. Điều này kéo theo các thành phần bổ sung như reverse proxy để đảm bảo an ninh, các dịch vụ phụ trợ cho xác thực, và logic tích hợp tùy chỉnh. Mỗi thành phần đều làm tăng chi phí vận hành và độ phức tạp, do cần triển khai, bảo mật, vá lỗi, giám sát và bảo trì riêng.
Kết quả là, dù việc chia sẻ dữ liệu từ lưu trữ on-premises sang môi trường tính toán trên đám mây là khả thi, con đường để đạt được điều đó vẫn còn phức tạp. Với các tổ chức muốn triển khai phân tích dữ liệu lai (hybrid analytics) mà không mở rộng hạ tầng đáng kể, đây là một rào cản lớn.
Khi Delta Sharing được tích hợp trực tiếp vào Object Storage
Object storage là lớp nền tảng của kiến trúc data lakehouse hiện đại – nơi dữ liệu thực sự tồn tại. Câu hỏi đặt ra là tại sao không tận dụng lớp này để gánh vác nhiều hơn cho các khối lượng công việc hiện đại, bằng cách tập trung hạ tầng, bảo mật và quản trị vào một điểm duy nhất.
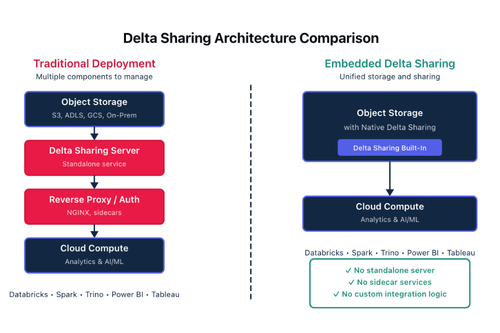
Trong những năm gần đây, nhiều API lakehouse đã được tích hợp trực tiếp vào các hệ thống object storage on-premises và hybrid. Việc tích hợp Delta Sharing cũng theo cùng một tư duy này.
Thay vì triển khai một máy chủ chia sẻ dữ liệu độc lập, khả năng chia sẻ sẽ trở thành một chức năng gốc của nền tảng lưu trữ. Các chia sẻ dữ liệu được định nghĩa, bảo mật và công bố ngay từ hệ thống lưu trữ – chính nơi dữ liệu được lưu trữ.
Lợi ích chính của kiến trúc này
Đơn giản hóa kiến trúc
Mỗi thành phần bổ sung trong kiến trúc dữ liệu đều kéo theo chi phí triển khai, cấu hình, bảo mật và bảo trì. Khi Delta Sharing được tích hợp trực tiếp vào object storage, toàn bộ một lớp hạ tầng trung gian được loại bỏ. Không còn máy chủ Delta Sharing riêng biệt, không có dịch vụ phụ trợ hay logic tích hợp tùy chỉnh, và cũng không cần một mặt phẳng quản trị độc lập phải đồng bộ với chính sách lưu trữ.
Lưu trữ và chia sẻ dữ liệu được hợp nhất trong một hệ thống duy nhất, giúp đội ngũ nền tảng và hạ tầng giảm đáng kể gánh nặng vận hành và hạn chế các điểm lỗi tiềm ẩn.
Loại bỏ việc sao chép dữ liệu
Trong các mô hình phân tích lai, việc sao chép dữ liệu từ on-premises lên đám mây là rất phổ biến. Tuy nhiên, cách làm này làm phát sinh chi phí lưu trữ, chi phí tính toán cho các tác vụ đồng bộ và chi phí vận hành để quản lý pipeline.
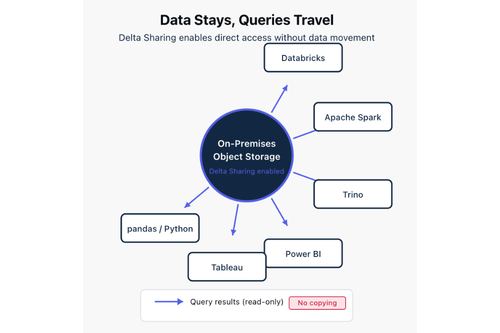
Với Delta Sharing tích hợp sẵn, dữ liệu on-premises có thể được truy cập trực tiếp bởi các engine tính toán, dù chạy trên Databricks, Spark tại chỗ hay các môi trường khác. Dữ liệu không cần di chuyển; chỉ kết quả truy vấn được truyền đến nơi cần thiết. Điều này loại bỏ tình trạng sai lệch phiên bản và đảm bảo một nguồn dữ liệu duy nhất, nhất quán cho tất cả người dùng.
Rút ngắn thời gian tạo insight
Các phương pháp chia sẻ dữ liệu truyền thống thường yêu cầu sao chép hàng terabyte dữ liệu trước khi phân tích, gây trễ và tạo ra các bản snapshot nhanh chóng lỗi thời. Delta Sharing cho phép truy vấn trực tiếp dữ liệu “sống”.
Khi Delta Sharing được tích hợp ở lớp lưu trữ, truy vấn không cần đi qua máy chủ trung gian, giúp giảm độ trễ và tăng tốc độ phân tích. Nhà phân tích và nhà khoa học dữ liệu có thể làm việc với dữ liệu hiện thời thay vì các bản sao cũ.
Kiểm soát và tối ưu chi phí
Việc kiểm soát lớp lưu trữ đồng nghĩa với việc kiểm soát dữ liệu. Mô hình chia sẻ lai cho phép doanh nghiệp giữ dữ liệu tại chỗ để tối ưu chi phí hoặc tuân thủ quy định, trong khi vẫn tận dụng các công cụ AI/ML trên đám mây. Điều này đặc biệt có giá trị với các tổ chức sở hữu khối lượng dữ liệu lớn hoặc chịu ràng buộc nghiêm ngặt về nơi lưu trữ dữ liệu.
Quản lý vòng đời bảng và chia sẻ thống nhất
Khi vòng đời của bảng dữ liệu và vòng đời chia sẻ được quản lý đồng thời, việc quản trị dữ liệu trở nên đơn giản hơn. Điều này đặc biệt hiệu quả trong các môi trường sử dụng catalog Iceberg tích hợp, nơi metadata và chính sách chia sẻ có thể được điều phối đồng bộ. Mọi thay đổi đối với bảng dữ liệu sẽ ngay lập tức được phản ánh trong các chia sẻ, không cần quy trình cập nhật riêng biệt.
Thực thi bảo mật ở cấp lưu trữ
Delta Sharing được thiết kế ở chế độ chỉ đọc. Khi nguyên tắc này được thực thi trực tiếp tại lớp lưu trữ – nơi dữ liệu vật lý tồn tại – mức độ đảm bảo an toàn cao hơn nhiều so với việc áp dụng quyền truy cập ở lớp tính toán. Điều này giảm thiểu rủi ro do cấu hình sai hoặc sai lệch quyền truy cập trong các dịch vụ tính toán.
Tương thích với hệ sinh thái lakehouse
Để đảm bảo tính tương thích, Delta Sharing tích hợp cần tuân thủ đặc tả Delta Sharing 1.0 và vượt qua các bài kiểm thử chính thức. Điều này đảm bảo rằng cùng một bảng dữ liệu có thể được sử dụng đồng thời bởi nhiều engine và công cụ khác nhau như Power BI, Databricks hay Spark, đúng với tinh thần mở và linh hoạt của kiến trúc lakehouse.
Các kịch bản sử dụng
Delta Sharing tích hợp đặc biệt phù hợp với các mô hình phân tích lai. Doanh nghiệp có thể công bố các tập dữ liệu on-premises cho Databricks mà không cần sao chép. Các bộ phận nghiệp vụ có thể truy vấn dữ liệu trực tiếp từ Power BI hoặc Tableau với thông tin luôn được cập nhật. Các quy trình AI/ML lai được hưởng lợi khi dữ liệu huấn luyện hoặc feature store nằm tại chỗ nhưng vẫn cần truy cập từ notebook trên đám mây. Với các khối lượng công việc nhạy cảm về tuân thủ như giao dịch tài chính hoặc dữ liệu an ninh, Delta Sharing cung cấp quyền truy cập chỉ đọc, đáp ứng đồng thời yêu cầu quản trị và phân tích hiện đại.
Tương lai là API
Delta Sharing nên trở thành một phần trực tiếp của object storage. Khi đó, dữ liệu on-premises sẽ thực sự trở thành một thành phần trung tâm trong kiến trúc data lakehouse, có thể được truy cập bởi bất kỳ công cụ nào hỗ trợ giao thức Delta Sharing. Không cần máy chủ trung gian, không cần dịch vụ phụ trợ, không cần mã tích hợp tùy chỉnh. Dữ liệu được giữ nguyên tại nguồn, nhưng vẫn tham gia đầy đủ vào các quy trình phân tích và AI hiện đại.
Unitas cam kết đồng hành cùng doanh nghiệp, cung cấp các giải pháp và phân tích an ninh mạng tiên tiến nhất. Để nhận được tư vấn chuyên sâu hoặc hỗ trợ nhanh chóng, vui lòng liên hệ với chúng tôi qua email: info@unitas.vn hoặc Hotline: (+84) 939 586 168.




