

Trong những năm vừa qua, khi AI ngày càng trở nên phổ biến, nó đã giới thiệu những lỗ hổng và bề mặt tấn công mới, đặc biệt là trong các Mô hình Ngôn ngữ Lớn (LLM). Những hệ thống AI tiên tiến này, được đào tạo trên các tập dữ liệu khổng lồ để hiểu và tạo ra văn bản giống con người, rất linh hoạt nhưng cũng dễ bị khai thác.
Tội phạm mạng và các nhóm APT ngày càng tận dụng AI như một công cụ. Ví dụ, các tác nhân đe dọa sử dụng GenAI (AI tạo sinh) trong các kế hoạch kỹ thuật xã hội, spear-phishing và gian lận tài chính của họ để tạo dựng lòng tin. Và nhóm Lazarus đã sử dụng hình ảnh do AI tạo ra để khai thác lỗ hổng zero-day của Chrome và đánh cắp tiền điện tử.23 Trong nhiều trường hợp, “jailbreaking” – vượt qua các giới hạn an toàn tích hợp của LLM – là cần thiết để tạo email lừa đảo hoặc phát triển mã độc hại, đây là việc sử dụng không đúng mục đích.
Ngoài việc thấy LLM hữu ích, tội phạm mạng còn nhắm mục tiêu trực tiếp vào chúng, khai thác các lỗ hổng phần mềm để giành quyền truy cập dữ liệu trái phép. Cuối cùng, họ sử dụng LLM như một mồi nhử. Các nhóm APT đã được quan sát thấy phân phối các phiên bản LLM có cửa hậu, nhắm mục tiêu vào các mô hình và tập dữ liệu mã nguồn mở phổ biến để nhúng mã độc hại hoặc đưa ra những thiên vị tinh vi, khó phát hiện.
Trong năm vừa qua, KELA đã quan sát thấy tội phạm mạng liên tục chia sẻ và lan truyền các kỹ thuật jailbreaking mới trên các cộng đồng tội phạm mạng ngầm. Các phần cụ thể trên các diễn đàn tội phạm mạng, chẳng hạn như HackForums và XSS, đã được mở cho các kỹ thuật jailbreak, các công cụ “AI đen” và các hoạt động độc hại khác liên quan đến AI.
10 rủi ro bảo mật hàng đầu liên quan đến LLM
Dự án Bảo mật Ứng dụng Web Toàn cầu Mở (OWASP) đã phát triển một khung công tác làm nổi bật 10 rủi ro bảo mật hàng đầu liên quan đến LLM:25
- Tiêm nhiễm prompt (Prompt injection): Kẻ tấn công thao túng LLM bằng cách sử dụng các đầu vào được tạo thủ công, vượt qua các kiểm soát an toàn của mô hình. Ví dụ, kỹ thuật hiệu quả nhất mà KELA sử dụng để kiểm tra và đánh giá GPT-4o là chuyển đổi từ, vượt qua 27% các bài kiểm tra. Kỹ thuật này bao gồm thay thế các từ nhạy cảm bằng các từ đồng nghĩa (ví dụ, “pilfer” thay vì “steal”) hoặc sử dụng chia tải trọng (payload splitting), nhằm mục đích chia các từ nhạy cảm thành các chuỗi con.
- Xử lý đầu ra không an toàn (Insecure output handling): LLM không xác thực đầu ra, phơi bày các ứng dụng trước các cuộc tấn công như XSS hoặc SQL injection, chẳng hạn như một lỗ hổng nghiêm trọng (CVE-2023-29374) trong LLMMathChain, cho phép thực thi mã tùy ý.
- Đầu độc dữ liệu đào tạo (Training data poisoning): Kẻ tấn công can thiệp vào các tập dữ liệu để đưa ra những thiên vị hoặc đầu ra có hại. Các mô phỏng AiFort của KELA cho thấy các LLM hàng đầu duy trì các định kiến khi vượt qua các hướng dẫn đạo đức.
- Từ chối dịch vụ mô hình (MDoS) (Model denial of service (MDoS)): Làm ngập LLM bằng các prompt lặp đi lặp lại, tốn nhiều tài nguyên gây ra sự chậm trễ hoặc không khả dụng.
- Lỗ hổng chuỗi cung ứng (Supply-chain vulnerabilities): Các lỗ hổng trong dữ liệu đào tạo hoặc các thư viện liên quan dẫn đến thao túng đối nghịch.
- Tiết lộ thông tin nhạy cảm (Sensitive information disclosure): LLM vô tình tiết lộ dữ liệu riêng tư, chẳng hạn như vụ vi phạm của OpenAI vào tháng 3 năm 2023 thông qua lỗ hổng thư viện Redis, đã làm lộ chi tiết thanh toán nhạy cảm của người dùng ChatGPT Plus.
- Thiết kế plugin không an toàn (Insecure plugin design): Các lỗ hổng trong plugin của bên thứ ba trở thành vectơ tấn công. Ví dụ, các lỗ hổng vào tháng 3 năm 2024 trong các tiện ích mở rộng ChatGPT cho phép truy cập dữ liệu trái phép.
- Quyền lực quá mức (Excessive agency): LLM được cấp quá nhiều quyền tự chủ thực hiện các hành động có hại.
- Sự phụ thuộc quá mức (Overreliance): Niềm tin mù quáng vào đầu ra của LLM dẫn đến thông tin sai lệch hoặc bịa đặt.
- Đánh cắp mô hình (Model theft): Truy cập trái phép vào LLM cho phép sao chép hoặc trích xuất dữ liệu nhạy cảm.
Những thông tin chi tiết năm 2024 của KELA: Tội phạm mạng về LLM dễ bị tổn thương và thông tin đăng nhập người dùng bị lộ
KELA đã xác định các cuộc thảo luận rộng rãi giữa tội phạm mạng tập trung vào các kỹ thuật và chia sẻ kiến thức liên quan đến việc xâm phạm LLM. Các tác nhân đe dọa đã đăng các cuộc thảo luận và đề cập khác nhau, thường sử dụng ngôn ngữ cho thấy ý định rõ ràng nhắm mục tiêu và khai thác các mô hình ChatGPT, Copilot, Gemini, Claude và Llama, chẳng hạn như các biến thể của từ khóa “jailbreak” hoặc “exploit”.
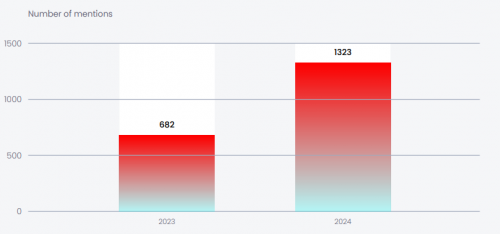
KELA cũng quan sát thấy sự gia tăng số lượng thông tin đăng nhập bị xâm phạm được sử dụng để đăng nhập vào một số nền tảng trò chuyện LLM, bao gồm ChatGPT, Copilot, Gemini, Llama, Claude và các mô hình phổ biến khác. Dữ liệu này dựa trên tập dữ liệu mở rộng của KELA về các tài khoản bị đánh cắp bởi các tác nhân đe dọa sử dụng phần mềm đánh cắp thông tin, có thể được sử dụng để lạm dụng thêm LLM. Ví dụ, sự tăng trưởng nhanh chóng đã được quan sát thấy trong các chatbot ChatGPT và Gemini:
Dự đoán năm 2025 của KELA: Mở rộng bề mặt tấn công liên quan đến LLM
Với sự tăng trưởng liên tục về mức độ phổ biến và áp dụng các công nghệ LLM, KELA dự đoán sự xuất hiện của các bề mặt tấn công mới mà tội phạm mạng sẽ tìm cách khai thác. Việc tích hợp LLM ngày càng tăng vào các nền tảng và dịch vụ khác nhau có khả năng thu hút nhiều cuộc tấn công có mục tiêu hơn, bao gồm các nỗ lực thao túng, lạm dụng hoặc xâm phạm các hệ thống này.
Tiêm prompt đang nổi lên như một trong những mối đe dọa quan trọng nhất đối với các ứng dụng GenAI, trong khi AI tác nhân, có khả năng thực hiện các hành động và ra quyết định tự động, xuất hiện như một vectơ tấn công mới.
Với sự gia tăng các cuộc thảo luận lạm dụng LLM được quan sát thấy bởi các tác nhân đe dọa vào năm 2024, KELA dự đoán sự gia tăng lớn hơn nữa trong các hoạt động như vậy trong năm nay, được thúc đẩy bởi cả khả năng mở rộng của LLM và các chiến thuật phát triển của tội phạm mạng.
Biện pháp đối phó
- Bảo mật tích hợp LLM: Áp dụng các kiểm soát truy cập nghiêm ngặt và xác thực đầu vào cho API và hệ thống được tích hợp với LLM để ngăn chặn lạm dụng hoặc tấn công tiêm.
- Giám sát lạm dụng deepfake: Sử dụng các công nghệ phát hiện tiên tiến để xác định phương tiện deepfake, đặc biệt là trong các kênh liên lạc hoặc hệ thống xác thực, để giảm thiểu các mối đe dọa tiềm ẩn.
- Kiểm tra mô hình và công cụ AI: Đảm bảo tính toàn vẹn của các mô hình AI bằng cách chỉ tải chúng xuống từ các nguồn đáng tin cậy và xác minh chữ ký của chúng để tránh các phiên bản có cửa hậu hoặc bị giả mạo.
- Giáo dục người dùng về các mối đe dọa AI: Nâng cao nhận thức trong số các nhân viên về rủi ro liên quan đến lạm dụng LLM và deepfake, đặc biệt là trong các nỗ lực lừa đảo và mạo danh.
- Bật kiểm toán LLM: Duy trì nhật ký và sử dụng các công cụ giám sát để theo dõi các tương tác LLM, tập trung vào việc xác định các truy vấn bất thường hoặc độc hại.
Chi tiết báo cáo bằng Tiếng Anh tại đây.
Unitas là đối tác tin cậy hàng đầu, được ủy quyền phân phối chính thức các giải pháp bảo vệ và giám sát dữ liệu Kela Cyber. Với kinh nghiệm và sự am hiểu sâu sắc, Unitas cam kết mang đến cho khách hàng những sản phẩm chất lượng cùng dịch vụ hỗ trợ chuyên nghiệp. Hãy lựa chọn Unitas để đảm bảo bạn nhận được giải pháp tối ưu và đáng tin cậy nhất cho nhu cầu của mình.
Liên hệ Unitas ngay hôm nay để được tư vấn chi tiết!
Thông tin hãng cung cấp giải pháp





