Trong vài tháng qua, trọng tâm của nhiều tổ chức IT là chuẩn bị cho làn sóng tăng giá RAM và NVMe SSD, cùng với tình trạng chậm giao server đang diễn ra trên diện rộng. Cũng trong khoảng thời gian đó, VergeOS 26.1 được phát hành với nhiều cải tiến quan trọng về data availability và data protection. Thoạt nhìn, hai vấn đề này có vẻ không liên quan. Nhưng trên thực tế, mối liên hệ giữa chúng là rất trực tiếp: khi phần cứng trở nên đắt đỏ hơn, khó mua hơn và buộc phải được sử dụng lâu hơn, thì data availability chính là lớp bảo vệ quyết định liệu sự cố phần cứng chỉ là một gián đoạn thông thường hay sẽ trở thành khủng hoảng vận hành.

Khi giá RAM tăng 50% hoặc hơn theo năm và thời gian chờ server mới kéo dài thêm nhiều tháng, các tổ chức thường phản ứng bằng cách kéo dài vòng đời phần cứng hiện có, gom workload lên ít server hơn, thậm chí cân nhắc sử dụng linh kiện refurbished. Tuy nhiên, mỗi chiến lược như vậy đều làm tăng xác suất phần cứng gặp lỗi. Trong bối cảnh đó, data availability không còn là một tính năng bổ sung, mà trở thành nền tảng cốt lõi giúp doanh nghiệp duy trì khả năng vận hành.
Bài toán này đã được phân tích chi tiết trong webinar theo yêu cầu “Right-Sizing Disaster Recovery with VergeOS 26.1”, nơi VergeOS giới thiệu các khả năng như per-resource replication, tag-based partial snapshots và protection tier framework. Bài viết này mở rộng thêm từ góc nhìn đó để làm rõ vì sao data availability lại đặc biệt quan trọng trong giai đoạn memory supercycle.
Thách thức khi kéo dài vòng đời server
Vấn đề khi tiếp tục sử dụng server cũ gần như không nằm ở CPU power. Trừ khi doanh nghiệp đang chạy các workload AI rất nặng, năng lực xử lý của phần lớn server hiện tại vẫn còn đủ dùng. Rào cản thực sự nằm ở quy luật hao mòn vật lý. Server càng cũ thì nguy cơ hỏng hóc bất ngờ càng cao: quạt xuống cấp, nguồn điện suy giảm, module bộ nhớ bắt đầu phát sinh lỗi với tần suất ngày càng lớn theo thời gian.
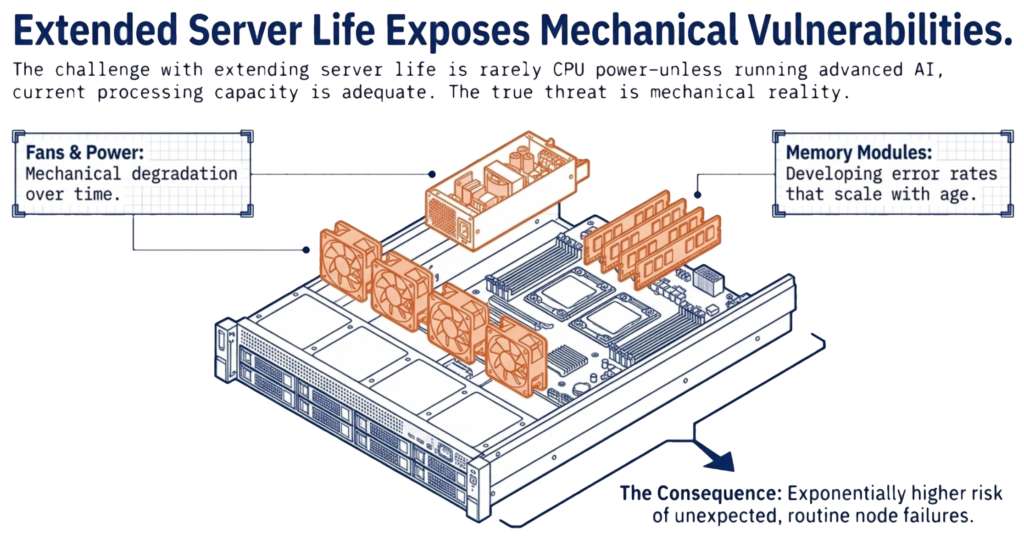
Khi một server gặp sự cố trong hạ tầng converged infrastructure, tác động thường lan rộng. Các máy ảo phải được chuyển sang các host còn sống. Trong một cụm hyperconverged infrastructure (HCI), việc mất một node đồng nghĩa với việc hệ thống ngay lập tức mất đi một tỷ lệ năng lực đáng kể. Ví dụ, một cụm HCI bốn node khi mất một node sẽ mất 25% tổng capacity. Các node còn lại vừa phải gánh thêm số VM bị displaced, vừa phải xử lý workload hiện hữu, đồng thời thực hiện quá trình rebuild dữ liệu từ node bị lỗi.
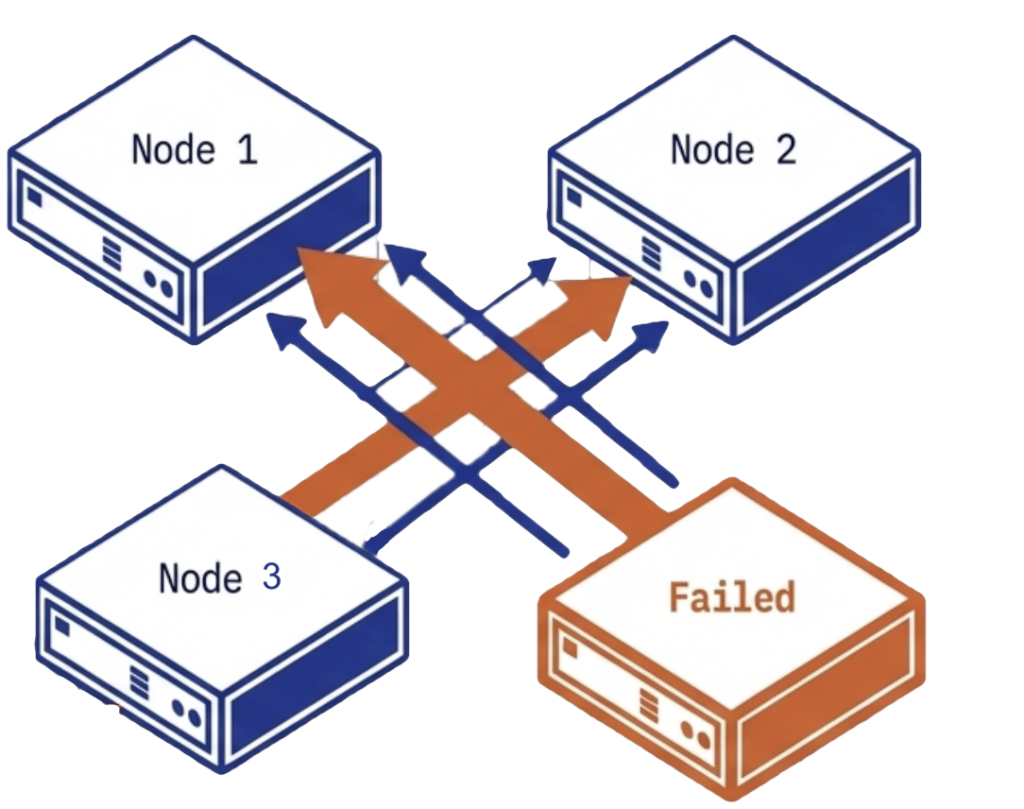 Nếu các node còn lại không còn đủ compute hoặc storage trống để hấp thụ phần 25% bị mất đó, cluster sẽ rơi vào trạng thái degraded, nơi một số VM thậm chí không thể khởi động lại. Những VM còn hoạt động sẽ phải cạnh tranh CPU, memory và I/O với tiến trình storage rebuild. Trong tình huống xấu nhất, chính tiến trình rebuild cũng thất bại vì cluster không còn đủ free disk space để tái replicate dữ liệu đã mất, khiến toàn bộ môi trường phải vận hành mà không còn redundancy cho đến khi quản trị viên bổ sung phần cứng mới. Trong giai đoạn supercycle, phần cứng thay thế đó có thể không về trong nhiều tuần hoặc nhiều tháng, biến một sự cố vốn chỉ gây bất tiện trở thành một khoảng thời gian rủi ro kéo dài.
Nếu các node còn lại không còn đủ compute hoặc storage trống để hấp thụ phần 25% bị mất đó, cluster sẽ rơi vào trạng thái degraded, nơi một số VM thậm chí không thể khởi động lại. Những VM còn hoạt động sẽ phải cạnh tranh CPU, memory và I/O với tiến trình storage rebuild. Trong tình huống xấu nhất, chính tiến trình rebuild cũng thất bại vì cluster không còn đủ free disk space để tái replicate dữ liệu đã mất, khiến toàn bộ môi trường phải vận hành mà không còn redundancy cho đến khi quản trị viên bổ sung phần cứng mới. Trong giai đoạn supercycle, phần cứng thay thế đó có thể không về trong nhiều tuần hoặc nhiều tháng, biến một sự cố vốn chỉ gây bất tiện trở thành một khoảng thời gian rủi ro kéo dài.
Nếu cụm HCI còn phụ thuộc vào data locality để che giấu các giới hạn về hiệu năng, tác động tiêu cực sẽ càng nặng hơn khi sự cố xảy ra. Data locality hoạt động bằng cách giữ dữ liệu VM trên chính node đang chạy VM đó để giảm cross-node I/O. Nhưng khi node này bị lỗi, dữ liệu phải được phục vụ từ bản sao trên node khác, và lợi thế hiệu năng biến mất đúng vào thời điểm cluster đang chịu áp lực lớn nhất.
VergeOS giải quyết bài toán này ở cấp độ kiến trúc. Nền tảng sử dụng mô hình ultraconverged infrastructure (UCI), trong đó không phải mọi node đều phải cung cấp storage. Mức độ ảnh hưởng sẽ phụ thuộc vào loại node bị lỗi. Nếu một compute-heavy node gặp sự cố, ioOptimize sẽ chủ động tái phân bố VM để đạt hiệu năng tối ưu trên các host còn lại, trong khi việc truy cập dữ liệu không bị ảnh hưởng vì storage không gắn chặt với node đã mất. Nếu một storage-heavy node bị lỗi, rất ít VM cần phải migrate và truy cập dữ liệu sẽ được chuyển hướng qua các synchronous mirror copy mà không làm giảm hiệu năng.
Nhờ tách biệt vai trò compute và storage, VergeOS tránh được tình huống dây chuyền trong đó VM migration, storage rebuild và cạn kiệt tài nguyên diễn ra cùng lúc. Đây là khác biệt lớn so với các kiến trúc HCI truyền thống.
VergeOS cũng không sử dụng data locality. Phần lớn lưu lượng dữ liệu của hệ thống luôn đi qua internode network ngay cả trong điều kiện vận hành bình thường, không chỉ khi xảy ra sự cố. Kết hợp giữa giao thức truyền thông internode tiên tiến và cơ chế deduplication trên toàn hạ tầng giúp giảm lưu lượng mạng từ 60–80%, hệ thống vẫn duy trì được độ trễ dưới 1 millisecond cho mọi yêu cầu dữ liệu giữa các node. Điều đó có nghĩa là không tồn tại “vách đá hiệu năng” ẩn khi một node bị offline, bởi VergeOS vốn không phụ thuộc vào local access ngay từ đầu. Hồ sơ hiệu năng trong lúc có sự cố cũng chính là hồ sơ hiệu năng hệ thống đang vận hành mỗi ngày.
Thách thức khi kéo dài vòng đời ổ đĩa
Các flash drive cũ cũng mang theo nguy cơ hỏng hóc cao hơn, nhưng điều đó không đồng nghĩa với việc sự cố phải đến một cách bất ngờ. Flash drive có thể tự theo dõi mức độ hao mòn, và phần mềm phù hợp sẽ giúp quản trị viên nhận được cảnh báo từ sớm trước khi ổ đĩa tiến đến trạng thái lỗi nghiêm trọng. Ở khía cạnh này, flash an toàn hơn hard disk truyền thống, vốn có thể chết đột ngột mà gần như không báo trước. Tuy nhiên, trong cả hai trường hợp, redundancy vẫn là yêu cầu bắt buộc. Vấn đề chỉ là mức độ redundancy cần bao nhiêu là hợp lý.
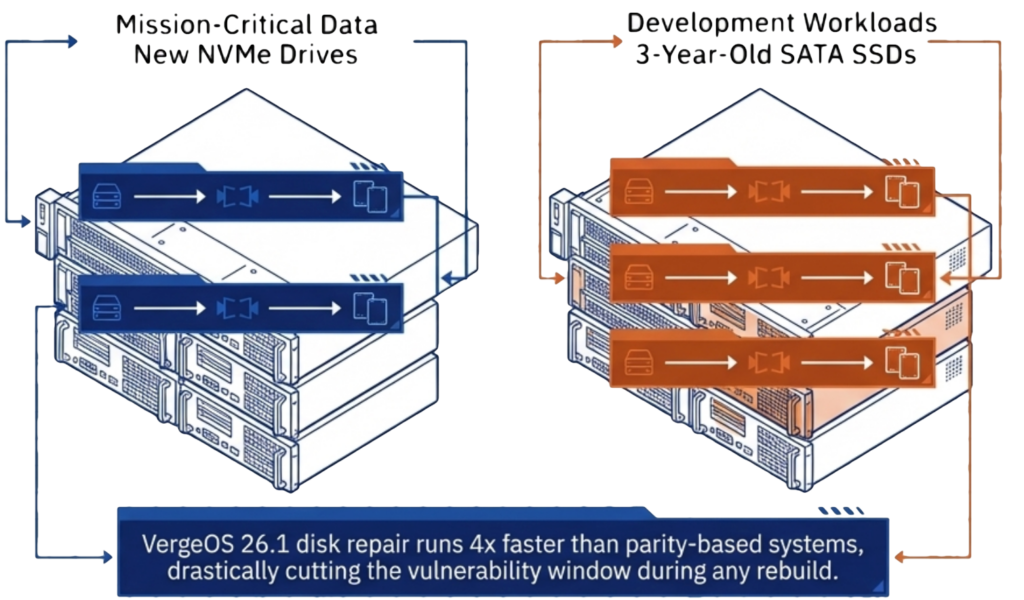 Mức redundancy phù hợp không nên được quyết định bởi tâm lý “càng nhiều càng tốt”, mà cần dựa trên loại ổ đĩa đang sử dụng, tuổi thọ của chúng và mức độ quan trọng của dữ liệu. Một nhóm node dùng NVMe mới để chạy workload Mission-Critical rõ ràng có profile rủi ro khác hoàn toàn với một nhóm node dùng SATA SSD ba năm tuổi cho môi trường test và development. Áp cùng một mức redundancy cho cả hai sẽ dẫn đến lãng phí ở bên này và under-protection ở bên kia.
Mức redundancy phù hợp không nên được quyết định bởi tâm lý “càng nhiều càng tốt”, mà cần dựa trên loại ổ đĩa đang sử dụng, tuổi thọ của chúng và mức độ quan trọng của dữ liệu. Một nhóm node dùng NVMe mới để chạy workload Mission-Critical rõ ràng có profile rủi ro khác hoàn toàn với một nhóm node dùng SATA SSD ba năm tuổi cho môi trường test và development. Áp cùng một mức redundancy cho cả hai sẽ dẫn đến lãng phí ở bên này và under-protection ở bên kia.
VergeOS cung cấp công cụ để doanh nghiệp thực hiện sự phân biệt đó. Nền tảng cho phép theo dõi chi tiết remaining useful life của từng ổ đĩa, bao gồm wear level tracking và hệ thống cảnh báo có thể tùy chỉnh khi ổ đĩa đạt đến ngưỡng hao mòn xác định trước. Nhờ vậy, quản trị viên có thể nhìn thấy xu hướng xuống cấp trước khi nó trở thành sự cố thực sự, từ đó chủ động lên kế hoạch thay thế thay vì phản ứng trong tình huống khẩn cấp.
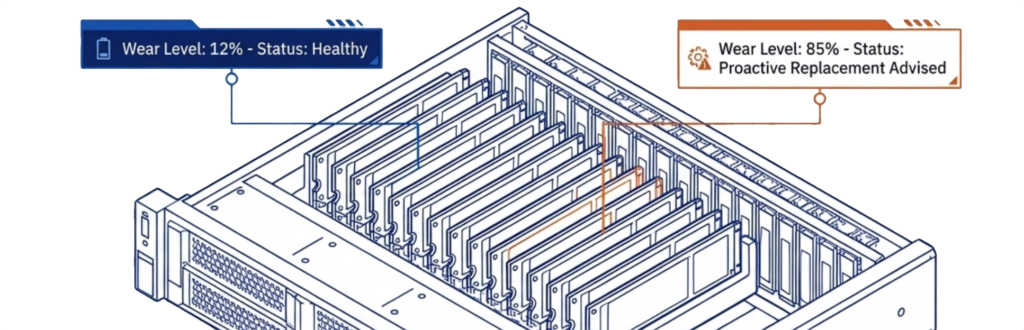
Cấu hình redundancy kiểu mirrored RF2 kết hợp với ioGuardian mang lại mức data availability N+2 cho phần lớn workload doanh nghiệp. Với các tổ chức đang dùng ổ đĩa cũ hoặc cần bảo vệ dữ liệu cực kỳ quan trọng, RF3 triple mirroring kết hợp ioGuardian sẽ cung cấp mức availability N+X. Cả hai tùy chọn đều sử dụng synchronous mirroring để rebuild từ các bản sao còn nguyên vẹn. Trong VergeOS 26.1, tốc độ disk repair đã nhanh gấp bốn lần so với bản trước, giúp rút ngắn thời gian dễ bị tổn thương xuống chỉ còn một phần nhỏ so với các hệ thống dựa trên parity.
ioGuardian: Mua thêm thời gian khi chưa thể thay phần cứng
Các kiến trúc storage truyền thống coi việc hỏng ổ đĩa hoặc node là sự cố cần thay thế ngay lập tức. Cluster sẽ phải chạy trong trạng thái degraded cho đến khi phần cứng mới được giao đến, lắp đặt xong và hoàn tất rebuild. Trong chuỗi cung ứng bình thường, khoảng thời gian này có thể kéo dài từ vài giờ đến vài ngày. Nhưng trong giai đoạn supercycle, nó có thể biến thành vài tuần hoặc vài tháng.
ioGuardian thay đổi hoàn toàn phương trình đó. Thay vì phải chờ phần cứng mới để khôi phục redundancy, ioGuardian sử dụng các repair server chuyên dụng để đưa những missing data block quay trở lại môi trường production. Các repair server này hoạt động bên ngoài đường I/O của production, vì vậy quá trình rebuild không tranh chấp CPU, memory hay disk bandwidth với workload đang chạy. Cluster có thể quay trở lại trạng thái full redundancy mà không cần phần cứng thay thế ngay lập tức.
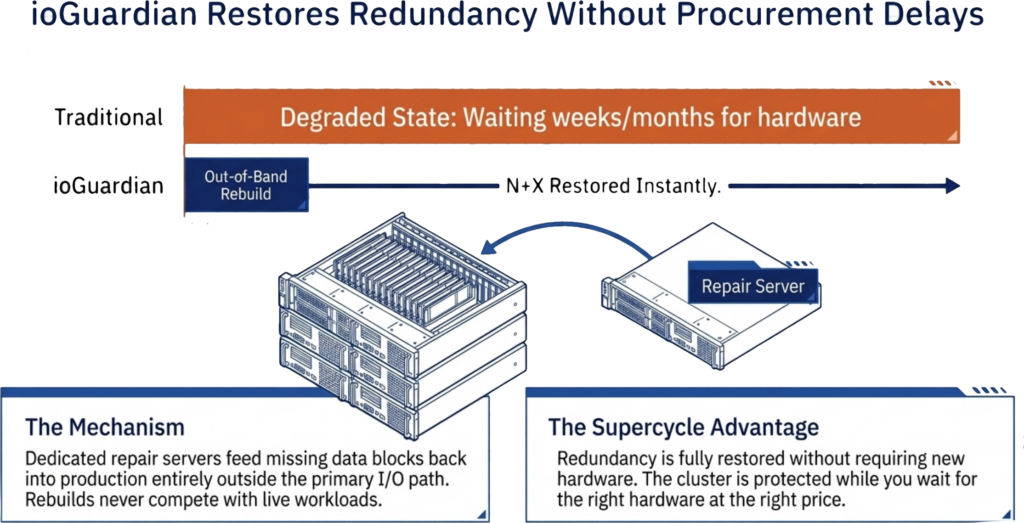
Điều này đặc biệt quan trọng trong giai đoạn supercycle vì hai lý do. Thứ nhất, nó loại bỏ áp lực phải mua ngay ổ đĩa hoặc server thay thế trong bối cảnh giá cả tăng cao và lead time khó đoán. Cluster vẫn được bảo vệ trong khi doanh nghiệp chờ đúng phần cứng với mức giá hợp lý hơn, thay vì phải trả premium chỉ để nhận hàng sớm. Thứ hai, nó xóa bỏ khoảng thời gian rủi ro vốn ngày càng nguy hiểm nếu kéo dài. Mỗi ngày một cluster truyền thống chạy trong trạng thái degraded là thêm một ngày nguy cơ mất dữ liệu nếu xuất hiện lỗi thứ hai. ioGuardian đóng lại khoảng trống đó bất kể quy trình mua sắm kéo dài bao lâu.
Khi kết hợp với RF2, ioGuardian mang lại mức availability N+2. Khi kết hợp với RF3 trong VergeOS 26.1, nó cung cấp mức N+X. Trong cả hai trường hợp, mức bảo vệ vẫn giữ nguyên cho dù phần cứng thay thế đến vào ngày mai hay quý sau.
Thách thức với phần cứng refurbished
Memory supercycle đang buộc nhiều tổ chức IT phải đối diện với một câu hỏi mà trước đây họ hiếm khi cân nhắc: có nên mua server, RAM và flash refurbished hay không? Xét về kinh tế, điều này hoàn toàn có lý. DDR4 refurbished rẻ hơn nhiều so với DDR5 mới. Những server cũ nhưng vẫn đủ CPU power thường có sẵn trên thị trường trong khi đơn hàng server mới phải chờ hàng tháng. Tuy nhiên, phần cứng refurbished đồng nghĩa với độ không chắc chắn cao hơn về vòng đời còn lại, và sự không chắc chắn đó đòi hỏi một kiến trúc bảo vệ đủ mạnh để hấp thụ tỷ lệ lỗi cao hơn.
VergeOS được thiết kế để vận hành tốt trên cả phần cứng mới, phần cứng cũ và các môi trường mixed hardware. Nền tảng có thể chạy trên commodity server thuộc nhiều thế hệ khác nhau, cho phép trộn nhiều loại server trong cùng một hệ thống và không yêu cầu cấu hình phần cứng phải đồng nhất theo vendor. Nhờ sự linh hoạt này, doanh nghiệp có thể triển khai phần cứng refurbished ở những vị trí hợp lý về mặt tài chính mà không cần phải thiết kế lại toàn bộ hạ tầng.
Kết hợp với ioOptimize, nền tảng còn có thể theo dõi tình trạng sức khỏe của phần cứng và chủ động migrate workload khỏi những node đang xuống cấp trước khi chúng gặp sự cố. Nhờ đó, phần cứng refurbished không còn là một canh bạc, mà trở thành một chiến lược tối ưu chi phí có kiểm soát.
Kết luận
Memory supercycle không phải là hiện tượng ngắn hạn. SK Hynix dự báo nguồn cung commodity DRAM sẽ còn bị siết ít nhất đến năm 2028. Trong bối cảnh đó, các tổ chức kéo dài vòng đời server, trì hoãn thay ổ đĩa và cân nhắc dùng phần cứng refurbished cần một nền tảng coi data availability là chức năng cốt lõi, chứ không phải add-on từ bên thứ ba.
VergeOS cung cấp mô hình data availability nhiều lớp, từ cấp ổ đĩa, cấp node cho đến cross-site replication, tất cả được tích hợp trong một nền tảng duy nhất có thể chạy trên phần cứng hiện hữu hoặc phần cứng refurbished mà doanh nghiệp buộc phải cân nhắc trong giai đoạn supercycle. Trong một thị trường mà chi phí bộ nhớ tăng cao và phần cứng mới ngày càng khó tiếp cận, khả năng đảm bảo dữ liệu luôn sẵn sàng không chỉ là yếu tố kỹ thuật. Nó là điều kiện tiên quyết để doanh nghiệp duy trì sự ổn định và liên tục trong vận hành.
Unitas cam kết đồng hành cùng doanh nghiệp, cung cấp các giải pháp và phân tích an ninh mạng tiên tiến nhất. Để nhận được tư vấn chuyên sâu hoặc hỗ trợ nhanh chóng, vui lòng liên hệ với chúng tôi qua email: info@unitas.vn hoặc Hotline: (+84) 939 586 168.