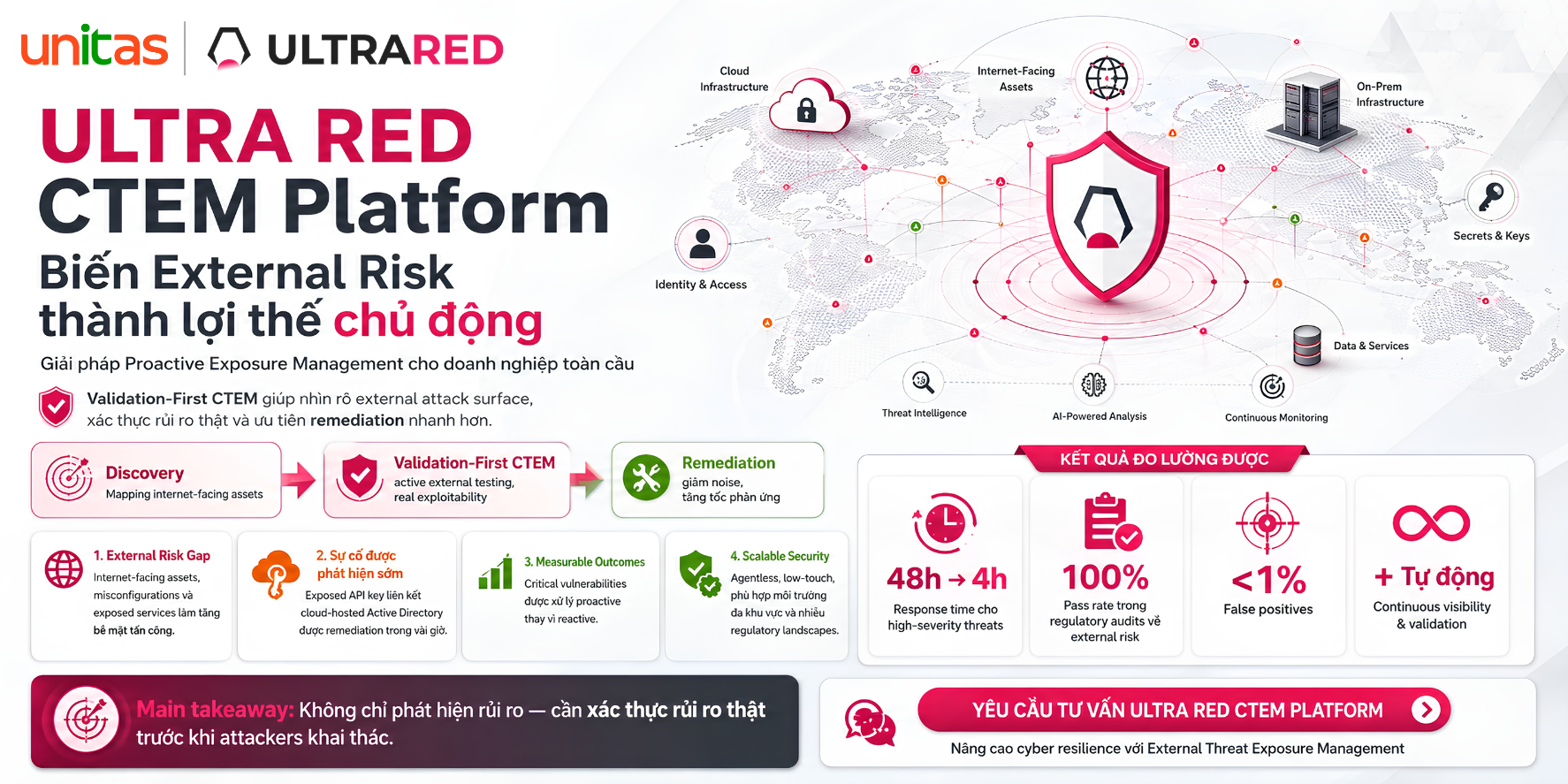
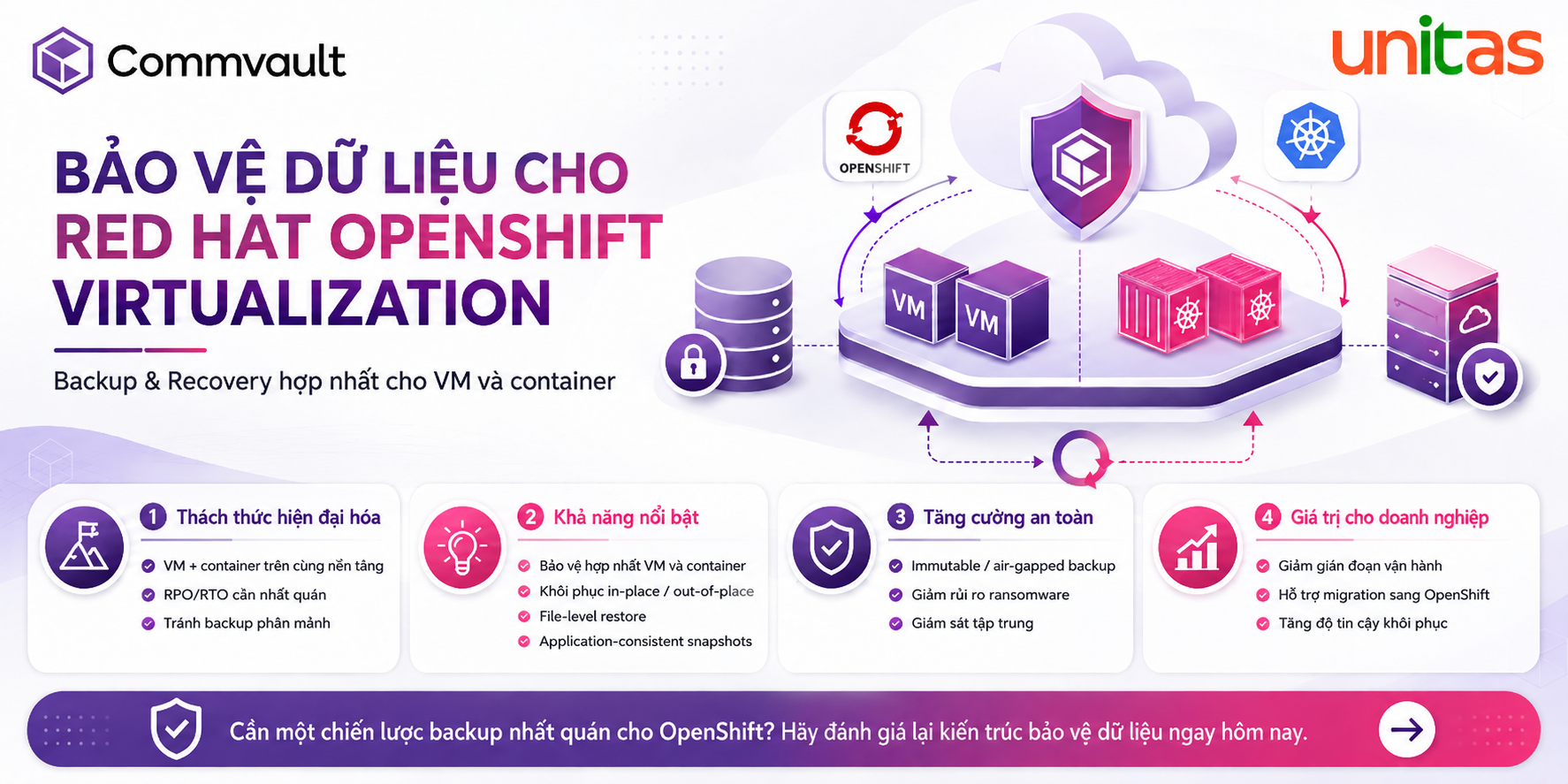
Khi các hệ thống quan trọng gặp sự cố, tổ chức phải đối mặt với một thực tế rõ ràng: mỗi phút gián đoạn đều gây tổn thất về chi phí, làm gián đoạn hoạt động và ảnh hưởng tiêu cực đến uy tín. Sự khác biệt giữa khả năng khôi phục nhanh chóng và tình trạng ngừng hoạt động kéo dài thường phụ thuộc vào hai quy trình cốt lõi: failover và failback.
Hai cơ chế này tạo nên nền tảng của các chiến lược sao lưu và khôi phục hiện đại, tuy nhiên nhiều đội ngũ CNTT vẫn gặp khó khăn trong việc triển khai hiệu quả hoặc phân biệt rõ vai trò của từng quy trình trong việc đảm bảo tính liên tục của hoạt động kinh doanh.
Việc hiểu rõ khi nào cần kích hoạt failover, cách quản lý quá trình chuyển đổi và quan trọng nhất là cách thực hiện failback thành công chính là yếu tố giúp các tổ chức vượt qua gián đoạn một cách vững vàng, thay vì chỉ cầm cự để tồn tại.
Sự Khác Biệt Giữa Failover Và Failback
Failover là quá trình chuyển hướng khối lượng công việc từ hệ thống chính sang môi trường dự phòng khi hệ thống chính không còn khả dụng. Quá trình này kích hoạt hạ tầng thứ cấp nhằm duy trì dịch vụ liên tục trong trường hợp xảy ra sự cố, dù nguyên nhân là lỗi phần cứng, tấn công mạng hay bảo trì theo kế hoạch.
Ví dụ, khi máy chủ cơ sở dữ liệu chính gặp sự cố, failover sẽ tự động chuyển toàn bộ truy vấn sang máy chủ dự phòng, cho phép các ứng dụng tiếp tục hoạt động trong khi đội ngũ kỹ thuật xử lý nguyên nhân gốc rễ.
Failback là quá trình ngược lại, đưa hoạt động từ môi trường dự phòng trở về hạ tầng chính ban đầu sau khi sự cố đã được khắc phục. Khác với tính phản ứng nhanh của failover, failback là một quá trình có chủ đích, được lập kế hoạch cẩn thận nhằm khôi phục trạng thái vận hành bình thường.
Chẳng hạn, nếu một doanh nghiệp phải vận hành từ trung tâm khôi phục thảm họa trong ba ngày do mất điện tại trung tâm dữ liệu chính, failback sẽ bao gồm việc di chuyển toàn bộ dịch vụ, dữ liệu phát sinh và kết nối người dùng trở lại trung tâm chính sau khi nguồn điện được khôi phục.
Đặc điểm của chuyển đổi dự phòng so với khôi phục dự phòng

Bảng sau đây cung cấp sự so sánh rõ ràng giữa các đặc điểm của quá trình chuyển đổi dự phòng và quá trình khôi phục dự phòng.
| Chức năng | Chuyển đổi dự phòng | Khôi phục dự phòng |
| Cò súng | Sự cố mất điện, thiên tai, hỏng hóc hoặc bảo trì | Giải quyết vấn đề ban đầu, khôi phục hệ thống. |
| Phương hướng | Chính → Phục hồi/Sao lưu | Khôi phục/Sao lưu → Chính |
| Mục tiêu | Tiếp tục ngay lập tức | Khôi phục hoạt động bình thường hoàn toàn |
| Đồng bộ dữ liệu | Có thể sử dụng bản sao lưu gần đây nhất | Phải đồng bộ hóa tất cả các thay đổi được thực hiện trong quá trình chuyển đổi dự phòng. |
| Tự động hóa | Thường được tự động hóa để tăng tốc độ. | Có thể cần thêm các bước kiểm tra và phối hợp. |
Failover Và Failback Trong Các Môi Trường Khác Nhau
Trong môi trường điện toán đám mây, failover được hỗ trợ thông qua cơ chế tự động mở rộng và phân bố địa lý. Ngược lại, các hệ thống tại chỗ (on-premises) yêu cầu phần cứng dự phòng được chuẩn bị sẵn.
Kiến trúc lai (hybrid) kết hợp cả hai cách tiếp cận: các khối lượng công việc quan trọng có thể failover sang đám mây để tăng tính linh hoạt, trong khi dữ liệu nhạy cảm vẫn được giữ trong hệ thống sao lưu tại chỗ nhằm đáp ứng yêu cầu tuân thủ.
Failover ưu tiên tốc độ hơn tối ưu hóa, trong khi failback đòi hỏi kế hoạch cẩn trọng để tránh mất mát dữ liệu. Failback yêu cầu đồng bộ toàn bộ các thay đổi phát sinh trong thời gian vận hành ở môi trường dự phòng và xác nhận rằng hệ thống chính có thể tiếp nhận lại khối lượng công việc.
Đồng bộ dữ liệu là thách thức lớn ở cả hai quy trình. Failover có thể chấp nhận mất mát dữ liệu tối thiểu để nhanh chóng khôi phục dịch vụ, trong khi failback phải xử lý toàn bộ giao dịch và thay đổi phát sinh, có thể mất nhiều giờ hoặc nhiều ngày tùy theo khối lượng dữ liệu.
Nhiều tổ chức lầm tưởng rằng failback diễn ra tự động hoặc rất nhanh sau khi hệ thống chính phục hồi. Trên thực tế, failback yêu cầu kiểm tra, xác thực và phối hợp chặt chẽ giữa các bộ phận, bao gồm xác minh tính ổn định của hệ thống, đồng bộ cơ sở dữ liệu, cập nhật DNS và giám sát hiệu suất trong suốt quá trình chuyển đổi.
Các Giai Đoạn Tích Hợp Trong Chiến Lược Khả Năng Phục Hồi Doanh Nghiệp
Một chiến lược failover và failback hiệu quả cần bao gồm giám sát liên tục cả hệ thống chính và hệ thống dự phòng, các cơ chế kiểm tra tự động để kích hoạt failover khi vượt ngưỡng cho phép, và kiểm thử định kỳ nhằm đảm bảo cả hai quy trình hoạt động đúng thiết kế.
Quy trình tích hợp toàn diện thường gồm các giai đoạn sau:
Giai đoạn đánh giá: Xác định các hệ thống quan trọng, thiết lập mục tiêu RPO và RTO, đồng thời phân tích mối phụ thuộc giữa các ứng dụng và hạ tầng.
Giai đoạn thiết kế: Xây dựng môi trường dự phòng đủ năng lực, cấu hình cơ chế sao chép dữ liệu và thiết lập kết nối mạng giữa các địa điểm.
Giai đoạn triển khai: Cài đặt công cụ tự động failover, cấu hình ngưỡng giám sát và xây dựng tài liệu hướng dẫn chi tiết.
Giai đoạn kiểm thử: Thực hiện các kịch bản giả lập sự cố, xác minh tính toàn vẹn dữ liệu sau failback và cải tiến quy trình dựa trên kinh nghiệm thực tế.
Giai đoạn tối ưu hóa: Phân tích kết quả kiểm thử, cải thiện thời gian khôi phục và cập nhật quy trình khi hạ tầng thay đổi.
Ma trận các Thực tiễn Tốt nhất và Lợi ích
Bảng này nêu bật những thực tiễn tốt nhất và lợi ích tương ứng của chúng:
| Thực hành tốt nhất | Lợi ích chính |
| Giám sát sức khỏe tự động | Giảm thời gian phát hiện từ hàng giờ xuống còn vài giây. |
| Kiểm tra chuyển đổi dự phòng định kỳ | Xác định những thiếu sót trước khi thảm họa thực sự xảy ra. |
| Sổ tay vận hành được ghi chép đầy đủ | Giúp thực hiện công việc một cách nhất quán bất kể nhân sự. |
| Phương pháp khôi phục từng bước | Giảm thiểu rủi ro hư hỏng dữ liệu trong quá trình trả về. |
| Phối hợp giữa các nhóm | Đảm bảo sự phù hợp giữa kỳ vọng của các bên liên quan về kỹ thuật và kinh doanh. |
Kiểm Thử Failover Và Failback
Quy trình kiểm thử hiệu quả cần xác nhận cả khả năng kỹ thuật lẫn mức độ sẵn sàng vận hành, bao gồm mô phỏng các kịch bản thảm họa, kiểm tra kích hoạt failover tự động và thủ công, xác minh đồng bộ dữ liệu trong failback, đảm bảo khả năng truy cập của người dùng và ghi nhận các vấn đề để cải tiến quy trình.
Nghiên Cứu Tình Huống: Hãng Du Thuyền Toàn Cầu
Một hãng du thuyền toàn cầu gặp thách thức lớn trong việc quản lý cấu hình DNS khi triển khai chiến lược khôi phục thảm họa trên đám mây. Doanh nghiệp cần đáp ứng mục tiêu RPO là 1 giờ cho ứng dụng quan trọng và 24 giờ cho các khối lượng công việc thông thường.
Giải pháp Commvault Cloud Rewind đã triển khai các quy trình failover và failback tùy chỉnh thông qua webhook lập trình, tích hợp với AWS Lambda để tự động quản lý DNS. Trong một kịch bản failover kéo dài 45 ngày, toàn bộ môi trường đã được tái tạo chỉ với một thao tác khôi phục duy nhất và sau đó được failback thành công mà không gây gián đoạn hoạt động.
Giải Pháp Commvault Cho Failover Và Failback
Commvault cung cấp khả năng khôi phục tự động hóa cho cả failover và failback thông qua nền tảng quản lý hợp nhất trên môi trường lai. Giải pháp hỗ trợ kích hoạt failover chỉ với một thao tác, xác thực máy ảo trước khi xảy ra sự cố và đồng bộ máy chủ dự phòng với hệ thống sản xuất nhằm giảm thời gian khôi phục.
Chiến lược failover và failback phù hợp sẽ giúp tổ chức nâng cao khả năng chống chịu trước cả các sự cố có kế hoạch và không có kế hoạch, đồng thời đảm bảo tính liên tục của hoạt động kinh doanh trong mọi tình huống.
Unitas cam kết đồng hành cùng doanh nghiệp, cung cấp các giải pháp và phân tích an ninh mạng tiên tiến nhất. Để nhận được tư vấn ch