Việc làm mới (refresh) hệ thống lưu trữ phá vỡ tự động hóa bởi vì các nhà cung cấp storage vận hành các dòng sản phẩm như những nền tảng độc lập, với API không tương thích với nhau. Khi doanh nghiệp đồng thời lên kế hoạch rời bỏ VMware, vấn đề này càng trầm trọng hơn, biến thành hai dự án thiết kế lại tự động hóa song song. Bài viết này giải thích vì sao việc refresh storage làm suy yếu Infrastructure-as-code và cách các nền tảng hạ tầng hợp nhất như VergeOS loại bỏ hoàn toàn nhu cầu phải viết lại tự động hóa.
Những điểm chính cần ghi nhớ
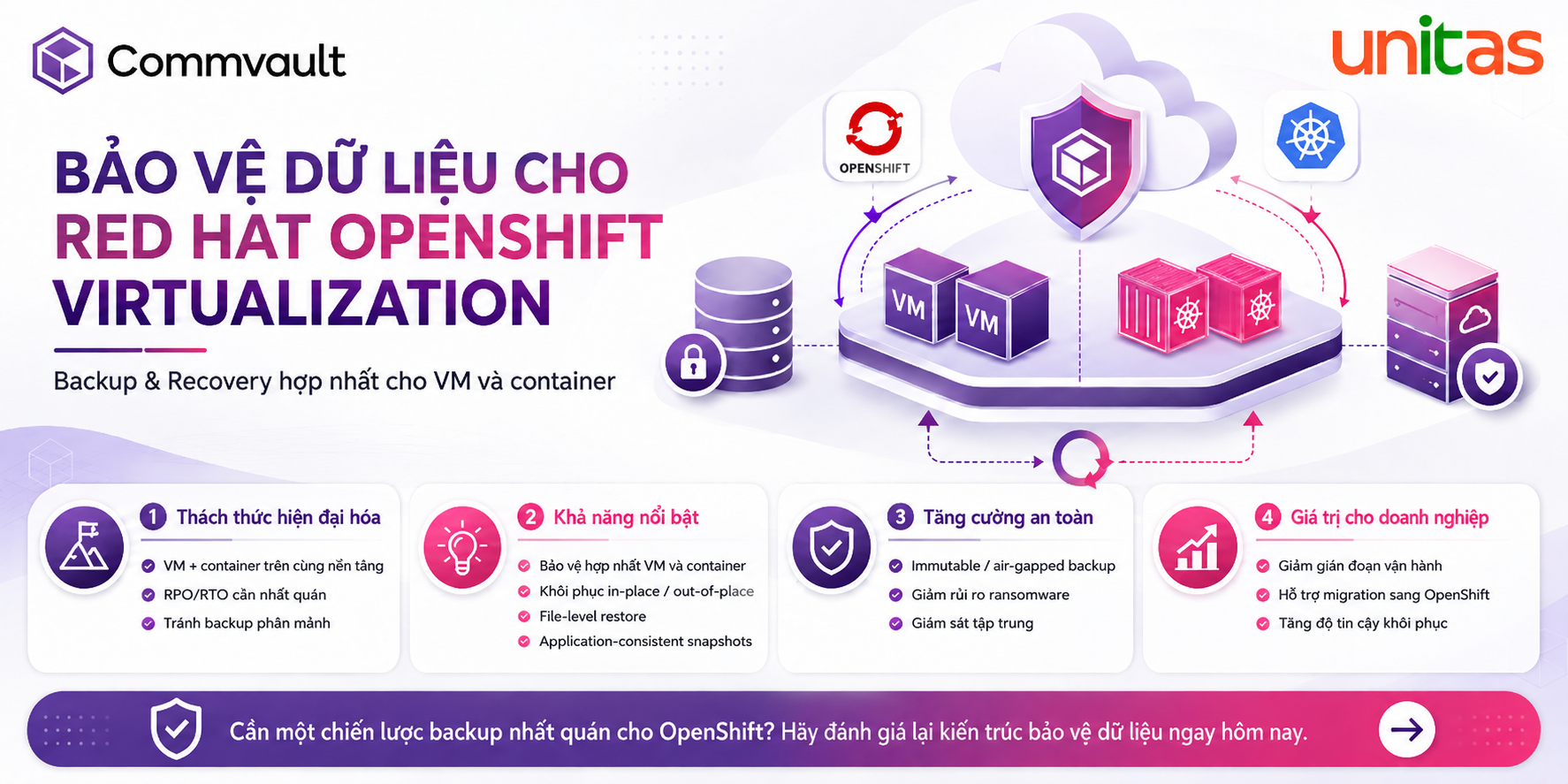
Vì sao các dự án refresh storage phá vỡ hệ thống tự động hóa đang hoạt động?
Hầu hết các tổ chức làm mới phần cứng lưu trữ mỗi 3-5 năm, với kỳ vọng đây chỉ là quá trình đơn giản gồm di chuyển dữ liệu, mở rộng dung lượng và loại bỏ thiết bị cũ. Tuy nhiên, trên thực tế, việc refresh thường biến thành một dự án thiết kế lại tự động hóa khi các thiết bị mới đi kèm firmware khác và API đã thay đổi.
Chu kỳ refresh tạo ra hàng loạt lỗi trong tự động hóa:
- Các storage refresh làm hỏng hệ thống tự động hóa
- Terraform provider thường chậm cập nhật so với firmware mới, khiến module không hoạt động
- API endpoint thay đổi giữa các thế hệ storage, làm hỏng code provisioning đang chạy tốt
- Cơ chế xác thực chuyển từ token sang OAuth hoặc CSRF
- Định nghĩa tài nguyên khác nhau giữa các dòng storage cũ và mới
- Công cụ monitoring/exporter không còn tương thích với firmware mới
Các nhóm kỹ thuật buộc phải lựa chọn giữa hai phương án tốn kém:
- Duy trì song song hai luồng tự động hóa trong giai đoạn chuyển tiếp, làm tăng gấp đôi chi phí bảo trì
- Dừng tự động hóa hoàn toàn để xây dựng lại từ đầu, đúng vào thời điểm tổ chức cần tự động hóa nhất – khi hạ tầng đang thay đổi lớn
Chu kỳ refresh bộc lộ một vấn đề cốt lõi: tự động hóa được xây dựng trên storage array sẽ kế thừa sự phân mảnh của chính storage. Khi phần cứng thay đổi, tự động hóa buộc phải thay đổi theo.
Thuật ngữ và khái niệm chính
Vấn đề refresh trong cùng một nhà cung cấp
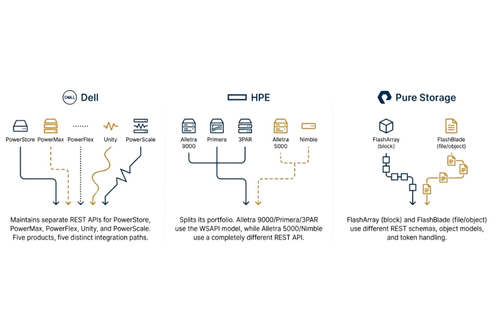
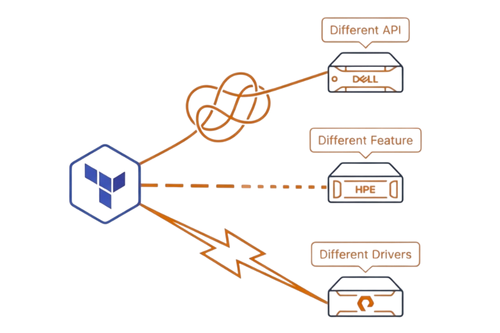
Nhiều tổ chức tiêu chuẩn hóa một nhà cung cấp storage với kỳ vọng rằng việc ở trong cùng hệ sinh thái sẽ bảo vệ khoản đầu tư vào tự động hóa. Thực tế lại gây thất vọng, vì các nhà cung cấp storage vận hành từng dòng sản phẩm như những nền tảng độc lập với API không tương thích. Do đó, việc refresh giữa các dòng sản phẩm khác nhau gần như đòi hỏi viết lại tự động hóa tương đương với việc đổi nhà cung cấp.
Ví dụ:
- Dell duy trì các REST API riêng biệt cho PowerStore, PowerMax, PowerFlex, Unity và PowerScale. Điều này khiến các module Terraform không thể tái sử dụng giữa các sản phẩm. Doanh nghiệp chuyển từ Unity sang PowerStore phải viết lại toàn bộ do khác biệt về định nghĩa tài nguyên, xác thực và cấu trúc JSON, dù vẫn dùng Dell.
- HPE chia danh mục sản phẩm theo kiến trúc: Alletra 9000/MP, Primera và 3PAR dùng WSAPI, trong khi Alletra 5000/6000 và Nimble dùng REST API hoàn toàn khác. Việc refresh từ 3PAR sang Nimble buộc phải viết lại toàn bộ Ansible playbook.
- Pure Storage sử dụng một REST schema cho FlashArray (block storage) và schema khác cho FlashBlade (file và object). Doanh nghiệp chuyển sang mô hình storage hợp nhất nhận ra rằng automation cho block không hoạt động với file workload, dù cùng thương hiệu.
Tiêu chuẩn hóa một nhà cung cấp giúp đơn giản hóa mua sắm nhưng không bảo vệ được tự động hóa trong chu kỳ refresh. Đội ngũ vẫn phải viết lại code tích hợp theo nền tảng, và hạ tầng phân mảnh tiếp tục phá vỡ tự động hóa.
Bẫy refresh đa thế hệ
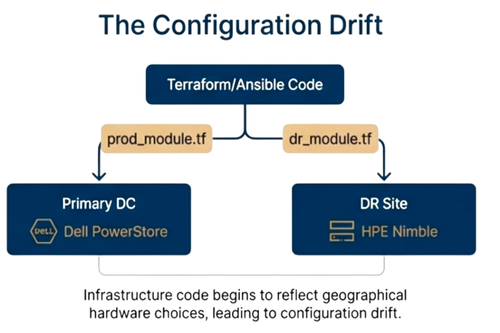
Chu kỳ refresh tạo ra sự lệch phiên bản giữa các môi trường: hệ thống production chạy trên storage cũ 3 năm, trong khi phần cứng mới dùng firmware và giao diện quản lý mới. Terraform module chạy tốt trong production nhưng thất bại ở môi trường test chỉ vì API đã thay đổi.
Do hạn chế ngân sách và yêu cầu quản trị rủi ro, tổ chức không thể refresh toàn bộ hệ thống cùng lúc. Trung tâm chính refresh trước, DR site sau 6 tháng, chi nhánh sau 18 tháng. Điều này buộc hệ thống tự động hóa phải hỗ trợ đồng thời nhiều thế hệ storage.
Các nhóm phải:
- Viết logic điều kiện để phát hiện firmware
- Thêm kiểm tra phiên bản trong Terraform
- Điều chỉnh Ansible playbook theo khả năng API
Thay vì trừu tượng hóa storage, code tự động hóa lại trở thành danh sách các “đặc thù firmware”.
Cơ chế xác thực cũng thay đổi theo thế hệ: từ token đơn giản sang session + CSRF hoặc OAuth. Những Ansible role từng chạy ổn định nhiều năm bỗng thất bại, buộc phải chỉnh sửa hàng trăm playbook.
Gánh nặng bảo trì tăng dần: vừa duy trì automation cho thế hệ N, vừa xây dựng cho N+1. Khi N+2 xuất hiện, hệ thống phải duy trì ba luồng code khác nhau, khiến nợ kỹ thuật ngày càng phình to.
Cái giá của việc đổi nhà cung cấp
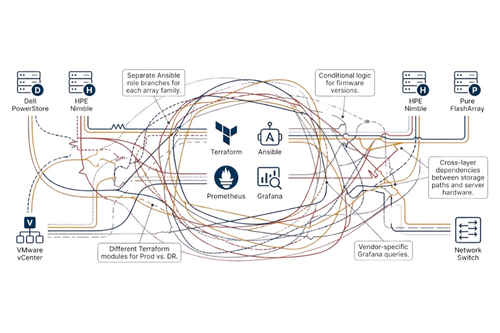
Khi đổi vendor trong chu kỳ refresh, tổ chức nhận ra vì sao refresh storage phá vỡ tự động hóa. Việc chuyển từ Dell PowerStore sang HPE Primera đòi hỏi viết lại toàn bộ Terraform module do khác biệt hoàn toàn về tài nguyên, xác thực và xử lý lỗi.
Vấn đề không chỉ dừng ở Terraform mà còn mở rộng sang:
- Ansible collection riêng theo vendor
- Exporter monitoring khác nhau, khiến dashboard Grafana phải xây dựng lại
- Sự không đồng nhất trong công cụ tự động hóa giữa các nhà cung cấp
Một số vendor hỗ trợ Terraform nhưng không hỗ trợ Ansible, và ngược lại. Điều này buộc đội ngũ vừa học lại công cụ, vừa viết lại code, vừa thay đổi quy trình vận hành.
Vấn đề tương tự cũng xảy ra ở hypervisor và network layer, nơi việc rời VMware hoặc refresh thiết bị mạng kéo theo những dự án thiết kế lại tự động hóa độc lập.
VergeOS loại bỏ độ phức tạp của refresh storage như thế nào?
VergeOS tiếp cận storage theo cách khác: tích hợp storage, compute và network vào một hệ điều hành duy nhất với một API chung. Storage chạy như một dịch vụ phân tán trên cluster thay vì là các array độc lập, từ đó loại bỏ sự gián đoạn trong tự động hóa khi refresh.
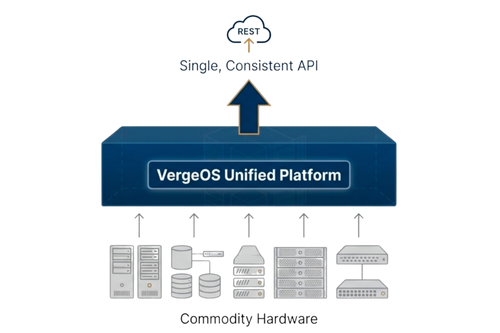
Các nhóm viết Terraform module tham chiếu đến dịch vụ storage, không phải phần cứng storage. Module provisioning volume hoạt động giống nhau dù ổ đĩa bên dưới là SSD SATA cũ hay NVMe mới.
Lợi ích tự động hóa khi refresh storage với VergeOS:
- Terraform module không cần thay đổi khi thêm server mới
- Ansible role hoạt động ổn định, không cần kiểm tra firmware
- Monitoring hiển thị metric nhất quán qua mọi thế hệ phần cứng
- Cơ chế xác thực không đổi dù thay hardware
- Lớp dịch vụ storage trừu tượng hóa ổ đĩa, server và firmware
- Các site refresh độc lập mà không cần nhánh code riêng
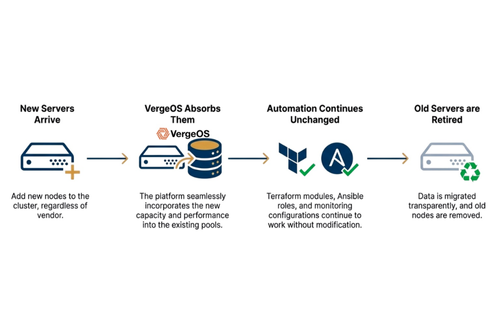
Việc refresh trở nên đơn giản: thêm server mới, loại server cũ, cluster tự điều chỉnh dung lượng mà automation không bị ảnh hưởng.
Vì sao việc rời VMware và refresh storage thường diễn ra cùng lúc?
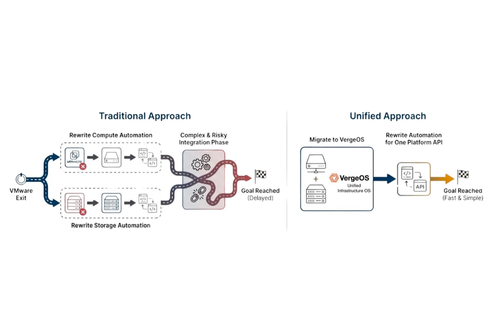
Nhiều tổ chức nhận ra storage sắp đến chu kỳ refresh đúng lúc họ cân nhắc rời VMware do chi phí license. Cách tiếp cận truyền thống xử lý hai việc này tuần tự, dẫn đến hai lần viết lại tự động hóa.
VergeOS cho phép kết hợp hai chuyển đổi này thành một, chỉ cần viết lại automation một lần duy nhất. Terraform và Ansible làm việc với hạ tầng hợp nhất thay vì các lớp riêng lẻ, giảm mạnh độ phức tạp.
Quyết định chiến lược với refresh storage
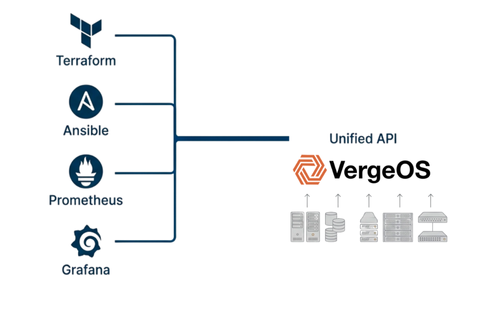
Chu kỳ refresh storage buộc tổ chức lựa chọn:
- Tiếp tục thay array mới và chấp nhận việc tự động hóa sẽ bị phá vỡ mỗi 3-5 năm
- Hoặc chuyển sang nền tảng hạ tầng hợp nhất, nơi storage không còn là yếu tố làm gián đoạn tự động hóa
VergeOS biến refresh storage thành sự kiện “vô hình” đối với automation, cho phép code hạ tầng tồn tại ổn định qua nhiều chu kỳ phần cứng.
Sự khác biệt này sẽ định hình hiệu quả vận hành của tổ chức trong nhiều năm tới.
Unitas cam kết đồng hành cùng doanh nghiệp, cung cấp các giải pháp và phân tích an ninh mạng tiên tiến nhất. Để nhận được tư vấn chuyên sâu hoặc hỗ trợ nhanh chóng, vui lòng liên hệ với chúng tôi qua email: info@unitas.vn hoặc Hotline: (+84) 939 586 168.